
2025-12-01-26f4122
This white paper answers the question “why is FeenoX different?” First of all, we have to say what FeenoX is. Then, we must state what we are comparing FeenoX against so we can finally explain why it is indeed different. TL; DR: FeenoX is different because there is nothing else that matches 100% FeenoX’s design and implementation.
As explained in its website, FeenoX is…
…a cloud-first free no-fee no-X uniX-like finite-element(ish) computational engineering tool.
or, in similar words,
…a tool to solve engineering-related problems using a computer (or many computers in parallel) with a particular design basis.
We will go into (some) of the details in sec. 3, but it is helpful to think of FeenoX as a transfer function between one or more input files and zero or more outputs:
+------------+
mesh (*.msh) } | | { terminal
input (*.fee) } input ---> | FeenoX |---> output { data files
data file } | | { post (vtk/msh)
+------------+Here, FeenoX is a binary executable which can be easily installed in a Debian or Ubuntu GNU/Linux server (remember it is a cloud-first tool) with
apt install feenoxLet us consider for instance the following input file that solves linear elasticity:
PROBLEM mechanical MESH box.msh
T(x,y,z) = sqrt(x^2 + y^2) + z # non-trivial temperature distribution
E = 200e3 * (1-T(x,y,z)/300) # temperature-dependent Young modulus
nu = 0.3
BC left fixed # left face fully fixed
BC top p=1e4*(1+x) # top face with a trapezFoidal load
WRITE_RESULTS FORMAT vtuSome preliminary notes:
PROBLEM
keyword at runtime. The same executable can solve several problems,
namely (so far in version 1.2 as the time of this writing)
laplace:
the Laplace equationthermal:
heat conductionmechanical:
mechanical elasticitymodal:
mechanical modal analysisneutron_diffusion:
core-level multi-group neutron diffusionneutron_sn:
core-level multi-group neutron transport with discrete ordinates.msh.vtk/.vtu formatsIn principle, nothing. FeenoX provides a Turing-complete system so theoretically any computable problem can be solved. Chances are that Tool \mathcal{X} also provides a Turing-complete system as well. So the question is ill-posed. The real question we need to ask is:
How much engineering effort is needed in order to solve problem y with FeenoX and with Tool \mathcal{X}?
Well, I do not know anything about Tool \mathcal{X}. But I do know everything about FeenoX and first of all, FeenoX is free1 software and open source so, again in principle, any engineer has the freedom to modify (or the freedom to hire someone to modify) the code to suit her needs.
But secondly and more importantly, FeenoX has been designed and implemented in such a way that solving problem y can be performed by different engineers as flexibly and efficiently as possible (i.e. in different ways for each engineer). Let us dive into some details in the next section.
For instance, given the question “what is the most efficient way of solving a maze?” there might be people that just say “Dijkstra” and move on. These are the same people that think they know more than they do and do not know what they do not know—especially regarding engineering challenges—as illustrated in FeenoX’s tutorial about solving mazes without AI.
FeenoX is a third-system effect. A first idea came up in the late 2000s. Since it had some good features, a second version with a lot of features appeared in the early 2010s. After almost one decade later, with all the lessons learned, the third version—named FeenoX—was re-written from scratch as a subject of a PhD thesis in Nuclear Engineering “Neutron transport in the cloud.”2
The design went through a pattern which is common in software development, namely
For FeenoX, these two documents—the SRS and the SDS—were written by the same person. But nevertheless, they help organize and understand the rationale behind the design and the implementation.
The main items of FeenoX’s design basis are
Technically speaking, FeenoX is a back end which can use zero or more front ends (fig. 1). These front ends can range from a graphical user interface that creates a proper input file given the user point-and-click choices down to an agent using an augmented Large Language Model to create the input from a problem formulated in natural (engineering) language.
Due to the way FeenoX is designed to read a text-based input file
(and eventually mesh and data files), it is perfectly suited to be run
in remote cloud servers. The server just needs to get the
feenox executable, either by (from easier and less flexible
to more complex and more flexible)
apt install feenox, orand either get or create on the fly the input and the mesh files.
These are actual files that can be uploaded from a client to a server,
copied from server to server and/or stored in any kind of medium until
needed. The same idea applies to the output, which being a set of files,
can be downloaded, copied or stored at will. There are no binary,
database nor proprietary lock ins. Hence, the implementation of a remote
REST API to handle file transfers from the client to the server back and
forth with a (possibly parallel) execution of feenox in the
middle is (almost) straightforward.3
The last three paragraphs illustrate item 1 (cloud-first remote execution) and 5.c (REST APIs).
Since the algebraic solvers in FeenoX are based on PETSc—if the server has enough computational power–it can be launched in parallel using the MPI standard. This architecture allows a large range of problem sizes to be tackled, from simple coarse cases up problems to millions of degrees of freedom since—as long as the server is part of an HPC cluster—the domain can be split not only among several processors but also among several nodes. This “distributed memory parallelization” approach is not bounded by the maximum memory of a single host as the “shared memory parallelization” scheme used by OpenMP.
The last paragraph illustrates item 2 (scalability with distributed-memory parallelization).
A great deal of effort was put into designing the syntax of the input files. The SDS discusses several “rules” for this syntax, but one of the most important ideas is the one from Alan Kay: “Simple things should be simple, complex things should be possible.” Another one is that the input file should try to match as closely as possible the “engineering” formulation of the problem. The inputs needed to solve two NAFEMS benchmark problems in fig. 2 and fig. 3 illustrate these concepts.


The last paragraph and figures 2-3 illustrate item 3 (self-descriptive English keyword-based plain-text input file).
Since the input files are based on English words and algebraic
expressions, they are amenable to be traced by version control systems
like Git. And since the mesh files come from Gmsh (actually from any
other mesher or converter that can write in .msh format)
that also uses English keywords in its input .geo language
(or in its Python API), in principle the set of files that completely
define a problem can be tracked with Git-like tools. Even more, FeenoX’s
source code is also tracked with Git and the feenox
executable reports its version and checksum when invoked with
-v so the same set of results can be deterministically
obtained:
$ feenox --versions
FeenoX v1.2.3-gf95b352
a cloud-first free no-fee no-X uniX-like finite-element(ish) computational engineering tool
Last commit date : Mon Sep 22 13:17:58 2025 -0300
Build architecture : linux-gnu x86_64
Compiler version : gcc (Debian 14.2.0-19) 14.2.0
Compiler expansion : gcc -Wl,-z,relro -Wl,-z,now -I/usr/lib/x86_64-linux-gnu/mpich/include -L/usr/lib/x86_64-linux-gnu/mpich/lib -lmpich
Compiler flags : -O3 -flto=auto -no-pie
GSL version : 2.8
SUNDIALS version : N/A
PETSc version : PETSc Development Git Revision: v3.24.1-181-gbad27f0b03b Git Date: 2025-11-24 16:54:37 +0000
PETSc arch : arch-linux-c-debug
PETSc options : --download-mumps --download-scalapack --download-slepc --with-bison=0 --with-c2html=0 --with-debugging=1 --with-x=0 --download-parmetis --download-metis
SLEPc version : N/AA set of scripts calling
feenoxcan help to get systematically traceable results. And even more so,
since the output from FeenoX is 100% determined by the user to the
extent that without instructions to create outputs (i.e. PRINT,
WRITE_RESULTS,
etc.) then there will not be any output whatsoever. There is no need to
for complex regular expressions or weird filter to uncover numerical
results buried inside thousands of useless lines of data. And since the
post-processing formats are standard (VTU/VTK or .msh) then
there are plenty of high-quality (and most of the time open source)
libraries for further post-processing the results and obtaining just the
numbers that the engineer needs, giving more importance to engineering
time over computer time. Plus, again since the output is user-defined,
programmatically creating plots, tables and even full engineering
reports is straightforward.
Moreover, FeenoX can expand command-line arguments into strings in the input file which—since everything is an expression—may be parsed as numerical values. For example, consider the following input that solves a rectangular cantilevered beam and computes the difference of the maximum displacement with the value predicted by Euler’s theory:
PROBLEM mechanical 3D MESH cantilever-$1-$2.msh
E = 2.1e11 # Young modulus in Pascals
nu = 0.3 # Poisson's ratio
F = 1000
BC left fixed
BC right Fz=-F # traction in Pascals, negative z
# compute the vertical displacement using Euler's theory
L = 0.5 # length
b = 0.05 # base
h = 0.02 # width
I = b*h^3/12
euler = -F*L^3/(3*E*I)
# error in z-displacement (components are u,v,w) at the tip vs. number of nodes
PRINT nodes %e 100*abs((w(L,0,0)-euler)/euler) "\# $1 $2"
The occurrences of $1 and $2 in the input
file are expanded to the arguments given in the command line after the
path to the input file. Hence, if we call Gmsh & FeenoX as
for e in tet4 tet10 hex8 hex20 hex27; do
for c in 1 0.75 0.5 0.2 0.1; do
gmsh -3 cantilever-$e.geo -clscale $c -o cantilever-$e-$c.msh -v 0
feenox beam-euler.fee $e $c | tee -a beam-euler-$e.dat
done
donewe can perform a parametric mesh convergence study. A result similar to fig. 4 can be easily created by standard open-source tools such as Gnuplot, Pyxplot or Matplotlib. Also, the combination of these parametric-ready features and the possibility of having sources (and material properties and boundary conditions) as algebraic expressions allow the verification of the solver with the Method of Manufactured solutions. Finally, by replacing a pre-defined parametric run with an optimization scheme one can smartly iterate over the parameter space to obtain optimal engineering designs.
The last four paragraphs illustrate item 4 (parametric and optimization studies) and 4.a (scriptability and traceability).
This design philosophy also enhances the creation of several front ends to match different needs. For instance, CAEplex is a web app that is integrated into the cloud-base CAD tool Onshape.
SunCAE is another front end that provides an open-source web interface that helps the user to create the mesh the CAD, create FeenoX’s input file, run the program and post-process the results. Even more, the input file can be edited online from the browser and, if the changes are simple enough, the web interface updates automatically. So for instance, if a boundary condition for a thermal problem says T=300~\text{K} then the input file would look like
BC bc1 T=300 GROUPS face9

Figure 5: Illustration of the two-way connection between the UX and the input file in SunCAE. a — FeenoX input file in the online editor, b — Updated interface with the new value
But if the user changes it to 250 and clicks “Accept” then the interface will show the updated value (fig. 5). Further examples of FeenoX usage through SunCAE:
The last three paragraphs illustrate item 5.b (straightforward integration with web-based UX/UIs).
The fact that feenox is an executable (instead of a
library) and that it reads the problem to be solved from an input file
at runtime (instead of having to recompile each time) allows LLMs to
assist the cognizant engineer in the process of stating the problem
formulation in FeenoX’s terms. Because the input syntax is designed to
look like engineering textbook descriptions (e.g.,
BC right T=300), LLMs can generate valid FeenoX inputs with
high accuracy. Unlike proprietary “input decks” full of magic numbers,
or GUI-based workflows that are invisible to an LLM, FeenoX provides a
semantic bridge between natural language and computational physics.
Furthermore, the feedback loop is tight: an LLM can write an input file,
run FeenoX, capture the standard error output, detect syntax errors
(e.g., a missing variable), correct the input, and run it again—all
without human intervention. This enables “Agentic workflows” where
the AI acts as a junior engineer, performing the setup and initial
debugging before the human reviews the results.
The last paragraph illustrates item 5.a (straightforward integration with LLMs).
This repository is an example of Kay’s idea that complex thing should be possible. It contains an example of scripts and input files that estimate environmentally-assisted fatigue in piping joints of a nuclear power plant using
Everything is Git-tracked and all the results are deterministically
computed by running a single script run.sh. By using
specific LaTeX macros, reports containing references to isometric blue
prints, time-dependent plots, spatial temperature distributions and
result tables can be created programmatically (such as the one shown
in fig. 6) without needing error-introducing manual interventions.
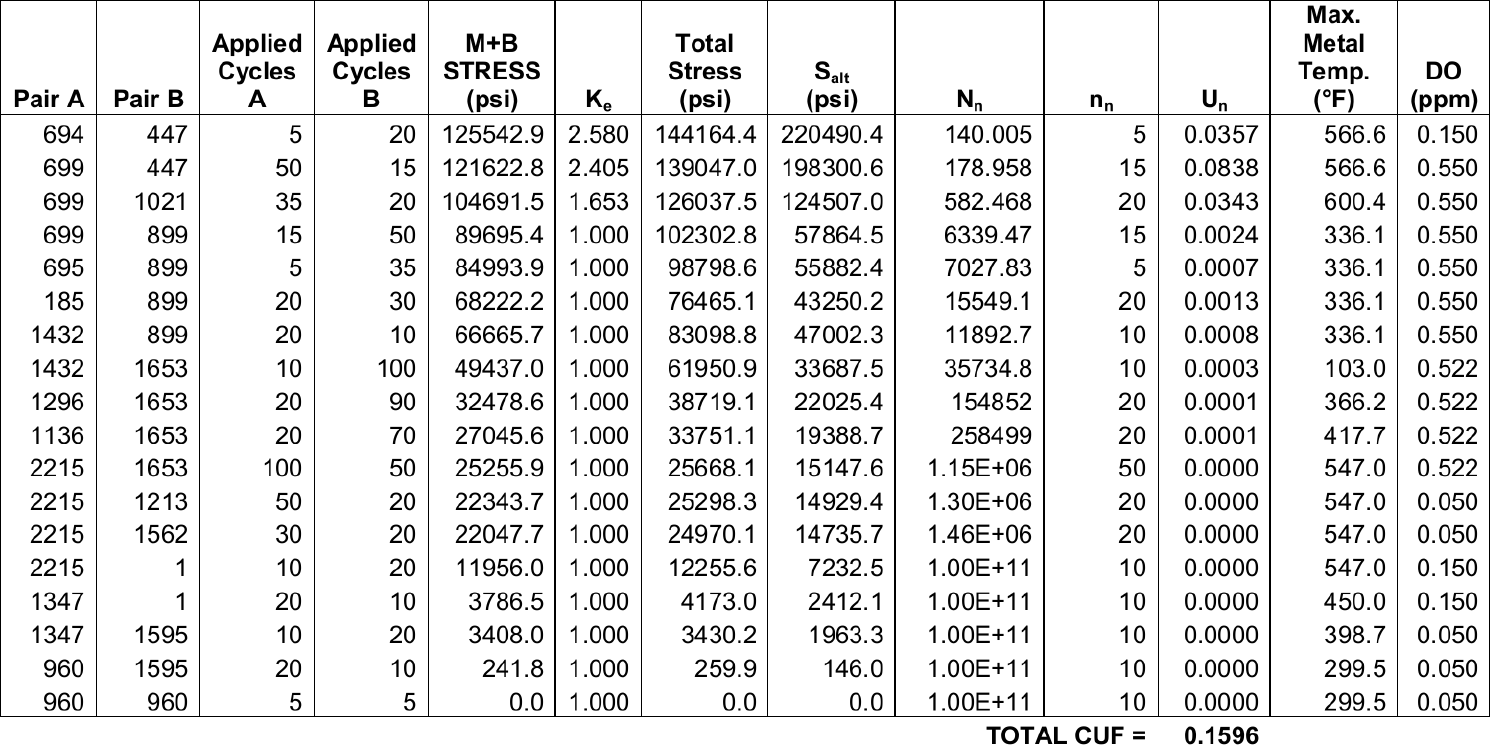
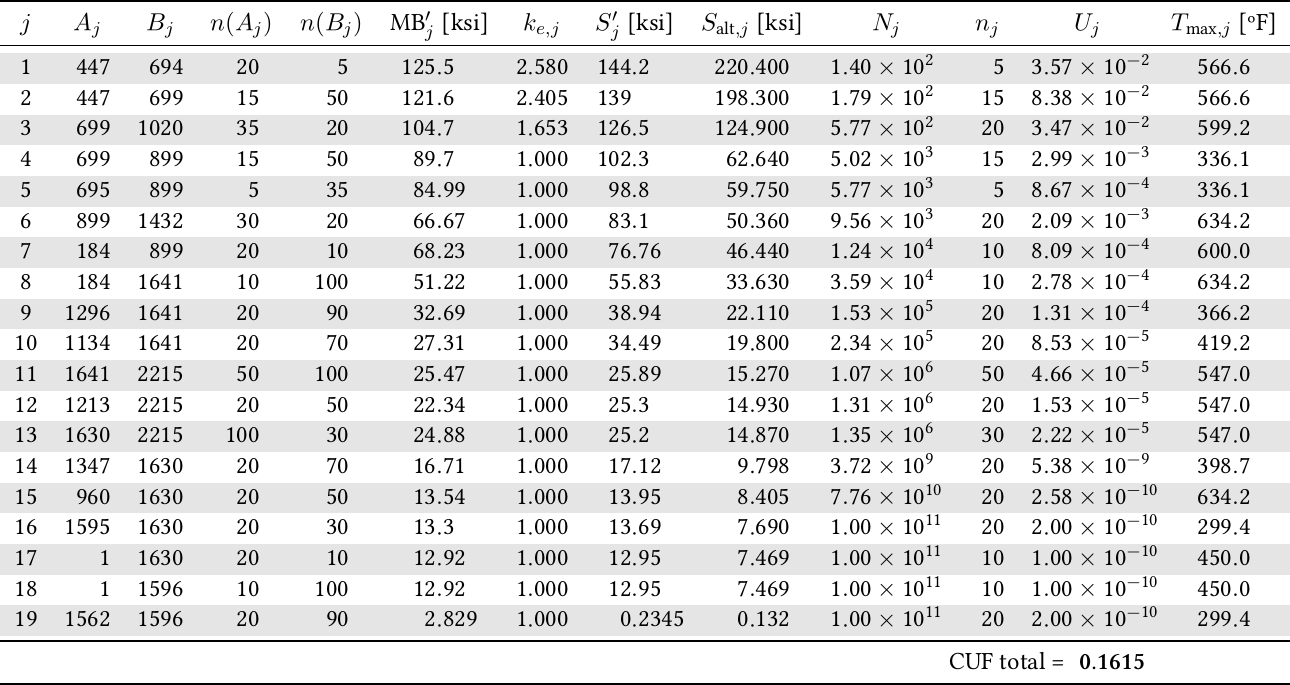
Figure 6: Results of the same environmentally-assisted fatigue problem.. a — A table published by a multi-billion-dollar agency (probably using Word), b — The same results in a report written by a a small third-world consulting company (FeenoX+AWK+LaTeX)
The last two paragraphs illustrate item 5.e (straightforward integration with Markdown and LaTeX reporting).
Taking into account the features discussed so far, it is left to the reader to consider the differences that FeenoX proposes with respect to traditional computational codes. In particular, to think about how the workflows in conceptual and basic engineering design of a nuclear reactor can be improved by being able to model all the physics involved in a nuclear reactor
Traditional computational codes in the nuclear industry…
Given what we have been discussing so far (and the details discussed in the SRS and the SDS), there is no single piece of software which provides all the benefits that FeenoX does.
| Feature | Traditional Commercial Code | FeenoX |
|---|---|---|
| Interface | Heavy GUI (User must click manually) | Text-based (Human or AI can write it) |
| Scalability | Expensive licenses per core; limited by license server | Unlimited MPI scaling; limited only by hardware |
| Transparency | “Binary files &”“Black Box”” solvers” | Plain text inputs & Open Source Code |
| Workflow | Monolithic (One tool does everything moderately well) | “Modular (Unix philosophy: connects with Gmsh, Paraview, Python)” |
| Reproducibility | Difficult (What version? Which settings?) | Native (Git-trackable inputs & versioned binaries) |
| AI Readiness | Low (Visual interfaces are hard for LLMs) | High (Text interfaces are native to LLMs) |
The goal is to provide a comprehensive suite of tools to aid engineering teams to design and license nuclear reactors within a modern philosophy that leverages state-of-the-art computational technologies (web, cloud, IA, etc.). The following is a list of potential development tasks that can move FeenoX closer to the aforementioned goal: