3 Esquemas de discretización numérica
You can know a great deal about something without writing about it. Can you ever know so much that you wouldn’t learn more from trying to explain what you know? I don’t think so. I’ve written about at least two subjects I know well—Lisp hacking and startups—and in both cases I learned a lot from writing about them.1 In both cases there were things I didn’t consciously realize till I had to explain them. And I don’t think my experience was anomalous. A great deal of knowledge is unconscious, and experts have if anything a higher proportion of unconscious knowledge than beginners.
Paul Graham, Putting Ideas into Words, 2022
Boundary conditions tend to make the theory of PDEs difficult.
Jürgen Jost, Partial Differential Equations, 2013 [8]
En el capitulo anterior hemos arribado a formulaciones matemáticas que modelan los procesos físicos de transporte y difusión de neutrones en estado estacionario mediante ecuaciones integro-diferenciales. Bajo las suposiciones que explicitamos al comienzo del capítulo 2 y asumiendo que las secciones eficaces macroscópicas son funciones del espacio y de la energía conocidas, estas ecuaciones son exactas. Para la ecuación de difusión, que es de segundo orden pero más sencilla de resolver, llegamos a
\tag{\ref{eq-difusion-ss}} \begin{gathered} - \text{div} \Big[ D(\mathbf{x}, E) \cdot \text{grad} \left[ \phi(\mathbf{x}, E) \right] \Big] + \Sigma_t(\mathbf{x}, E) \cdot \phi(\mathbf{x}, E) = \\ \int_{0}^{\infty} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \phi(\mathbf{x}, E^\prime) \, dE^\prime + \chi(E) \int_{0}^{\infty} \nu\Sigma_f(\mathbf{x}, E^\prime) \cdot \phi(\mathbf{x}, E^\prime) \, dE^\prime + s_0(\mathbf{x}, E) \end{gathered}
y para la ligeramente más compleja ecuación de transporte linealmente anisótropa obtuvimos
\tag{\ref{eq-transporte-linealmente-anisotropica}} \begin{gathered} \hat{\mathbf{\Omega}}\cdot \text{grad} \left[ \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \right] + \Sigma_t(\mathbf{x}, E) \cdot \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) = \\ \frac{1}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \int_{4\pi} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}^\prime, E^{\prime}) \, d\hat{\mathbf{\Omega}}^\prime\, dE^\prime + \\ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_1}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \int_{4\pi} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}^\prime, E^{\prime}) \cdot \hat{\mathbf{\Omega}}^\prime\, d\hat{\mathbf{\Omega}}^\prime\, dE^\prime \\ + \frac{\chi(E)}{4\pi} \int_{0}^{\infty} \nu\Sigma_f(\mathbf{x}, E^\prime) \cdot \int_{4\pi} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}^\prime, E^{\prime}) \, d\hat{\mathbf{\Omega}}^\prime\, dE^\prime + s(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \end{gathered}
sobre un espacio de fases generado2 por seis escalares independientes:
- tres para el espacio \mathbf{x},
- dos para la dirección \hat{\mathbf{\Omega}} y
- uno para la energía E.
El objetivo de este capítulo es transformar estas dos ecuaciones diferenciales en derivadas parciales en sistemas de ecuaciones algebraicas de tamaño finito de forma tal que las podamos resolver con una herramienta computacional, cuya implementación describimos en el capítulo 4. Este proceso involucra inherentemente aproximaciones relacionadas a la discretización de la energía E, la dirección \hat{\mathbf{\Omega}} y el espacio \mathbf{x}, por lo que las soluciones a las ecuaciones diferenciales que podamos encontrar numéricamente serán solamente aproximaciones a las soluciones matemáticas reales. Según discutimos en la Sección 3.1, estas aproximaciones serán mejores a medida que aumentemos la cantidad de entidades discretas. Pero al mismo tiempo aumentan los recursos y costos de ingeniería asociados.
Comenzamos primero entonces introduciendo algunas propiedades matemáticas de los métodos numéricos y discutiendo cuestiones a tener en cuenta para analizarlos desde el punto de vista del gerenciamiento de proyectos de ingeniería. Pasamos luego a la discretización de las ecuaciones propiamente dicha. Primeramente discretizamos la dependencia en energía aplicando la idea de grupos discretos de energías para obtener las llamadas “ecuaciones multigrupo”. Continuamos luego por la dependencia angular de la ecuación de transporte aplicando el método de ordenadas discretas S_N. Esencialmente la idea es transformar las integrales sobre E^\prime y sobre \hat{\mathbf{\Omega}}^\prime en las dos ecuaciones 2.62 y 2.41 del principio del capítulo por sumatorias finitas.
El grueso del capítulo lo dedicamos a la discretización espacial de ambas ecuaciones, que es el aporte principal de esta tesis al problema de la resolución de las ecuaciones de transporte de neutrones a nivel de núcleo utilizando mallas no estructuradas y técnicas de descomposición de dominio para permitir la resolución de problemas de tamaño arbitrario. En la monografía [15] mostramos, para la ecuación de difusión, una derivación similar a la formulación propuesta en esta tesis basada en elementos finitos. Pero también se incluye una formulación espacial basada en volúmenes finitos. Por cuestiones de longitud, hemos decidido enfocarnos solamente en elementos finitos en esta tesis. Dejamos la extensión a volúmenes finitos y su comparación con otros esquemas como trabajos futuros.
Finalmente analizamos la forma matricial/vectorial de los tres casos de problemas de estado estacionario que resolvemos en esta tesis:
- medio no multiplicativo con fuentes independentes
- medio multiplicativo con fuentes independientes
- medio multiplicativo sin fuentes independientes
3.1 Métodos numéricos
En forma general, las ecuaciones 2.62 y 2.41 que derivamos en el capítulo anterior a partir de primeros principios están expresadas en una formulación fuerte (ver definición 3.12) y exacta
\mathcal{F}(\varphi, \Sigma) = 0 denotando con
- \varphi el flujo incógnita (\psi o \phi) “exacto”3 que depende continuamente de \mathbf{x}, E y \hat{\mathbf{\Omega}},
- \Sigma todos los datos de entrada, incluyendo el dominio espacial de dimensión D continuo U \in \mathbb{R}^D y las secciones eficaces con sus dependencias continuas de \mathbf{x}, E y \hat{\mathbf{\Omega}},
- \mathcal{F} un operador integral sobre E^\prime y \hat{\mathbf{\Omega}}^\prime y diferencial sobre \mathbf{x}
Esencialmente, en este capítulo aplicamos métodos numéricos [11] para obtener una formulación débil (ver definición 3.13) y aproximada
\mathcal{F}_N(\varphi_N, \Sigma_N) = 0 \tag{3.1} donde ahora
- \varphi_N es una aproximación discreta de tamaño N del flujo incógnita,
- \Sigma_N es una aproximación de los datos de entrada, incluyendo una discretización U_N del dominio espacial
- \mathcal{F}_N es un operador discreto de tamaño N
El tamaño N del operador discreto \mathcal{F}_N es el producto de
- la cantidad G de grupos de energías (Sección 3.2),
- la cantidad M de direcciones de vuelo discretas (Sección 3.3), y
- la cantidad J de incógnitas espaciales (Sección 3.4).
Definición 3.1 (Convergencia) Un método numérico es convergente si
\lim_{N\rightarrow \infty} || \varphi - \varphi_N || = 0 para alguna norma apropiada ||\cdot||. Por ejemplo, para la norma L_2:
\lim_{N\rightarrow \infty} \sqrt{\int_U \int_{4\pi} \int_{0}^{\infty} \left[ \varphi(\mathbf{x},\hat{\mathbf{\Omega}},E) - \varphi_N(\mathbf{x},\hat{\mathbf{\Omega}},E) \right]^2 \, dE \, d\hat{\mathbf{\Omega}}\, d^3\mathbf{x} } = 0
La convergencia y, más aún, el orden con el cual el error || \varphi - \varphi_N || converge a cero es importante al verificar la implementación computacional de un método numérico. Tanto es así que para que una herramienta computacional sea verificada en el sentido de “verificación y validación” de software, no sólo se tiene que mostrar que \lim_{N\rightarrow \infty} || \varphi - \varphi_N || = 0 sino que la tasa de disminución de este error con 1/N tiene que coincidir con el orden del método numérico (ver Sección 5.9). De todas maneras, demostrar que un método numérico genérico es convergente no es sencillo y ni siquiera posible en la mayoría de los casos. En forma equivalente, se prueban los conceptos de consistencia y estabilidad definidos a continuación y luego se utiliza el teorema de equivalencia que sigue.
Definición 3.2 (Consistencia) Un método numérico es consistente si
\lim_{N\rightarrow \infty} \mathcal{F}_N(\varphi, \Sigma) = \lim_{N\rightarrow \infty} \left[ \mathcal{F}_N(\varphi, \Sigma) - \mathcal{F}(\varphi, \Sigma) \right] = 0
dado que \mathcal{F}(\varphi, \Sigma) = 0. Es decir, si el operador discreto \mathcal{F}_N tiende al operador continuo \mathcal{F} para N\rightarrow \infty entonces el método es consistente. Más aún, si
\mathcal{F}_N(\varphi, \Sigma) = \left[ \mathcal{F}_N(\varphi, \Sigma) - \mathcal{F}(\varphi, \Sigma) \right] = 0 \quad \forall N \geq 1 entonces decimos que el método numérico es fuertemente4 o completamente5 consistente.
Definición 3.3 (Estabilidad) Un método numérico es estable si dada una perturbación pequeña \delta \Sigma_N en los datos de entrada tal que
\mathcal{F}_N(\varphi_N + \delta \varphi_N, \Sigma_N + \delta \Sigma_N) = 0 entonces la perturbación \delta \varphi_N causada en la solución también es pequeña. Formalmente, un método numérico es estable si
\forall \epsilon > 0, \exists \delta(\epsilon) > 0 : \forall \delta \Sigma_N~/~ || \delta \Sigma_N || < \delta(\epsilon) \Rightarrow || \delta \varphi_N || < \epsilon \quad \forall N \geq 1
La consistencia es relativamente sencilla de demostrar. La estabilidad es un poco más compleja, pero posible. Finalmente, la convergencia queda demostrada a partir del siguiente resultado.
Teorema 3.1 (de equivalencia de Lax-Richtmyer) Si un método numérico es consistente, entonces es convergente si y sólo si es estable. Más aún, cualesquiera dos propiedades implica la tercera.
3.1.1 Comparaciones y evaluaciones económicas
Suponiendo que disponemos de varios métodos numéricos que nos permitan calcular \varphi_N a partir de un conjunto de datos de entrada \Sigma_N sobre un cierto espacio de fases discretizado, cabría preguntarnos cuál es el más eficiente para resolver un cierto problema de ingeniería nuclear. Está claro que en este sentido, la eficiencia depende de
la exactitud de la solución \varphi_N obtenida
los recursos computacionales necesarios para obtener \varphi_N, medidos en
- tiempo total de procesamiento (CPU, GPU y/o APU)
- tiempo de pared,6 que es igual al del punto a en serie pero debería ser menor en cálculos en paralelo,
- memoria RAM,
- necesidades de almacenamiento, etc.
los recursos humanos necesarios para
- preparar \Sigma_N (pre-procesar),
- analizar \varphi_N (post-procesar), y
- llegar a conclusiones útiles.
Si bien con esta taxonomía pareciera ser que comparar métodos numéricos no debería ser muy difícil, hay detalles que deben ser tenidos en cuenta y que de hecho complican la evaluación. Por ejemplo, dado un cierto problema de análisis de reactores a nivel de núcleo, el punto 1 incluye las siguiente preguntas:
- ¿Es necesario resolver la ecuación de transporte o la ecuación de difusión es suficiente?
- ¿Cuántas direcciones discretas hay que tener en cuenta para obtener una exactitud apropiada?
Por otro lado, el punto 2 abarca cuestiones como
- ¿Es más eficiente discretizar el espacio con una formulación precisa como Galerkin que da lugar a matrices no simétricas usando pocos grados de libertad o conviene utilizar una formulación menos precisa como cuadrados mínimos que da lugar a matrices simétricas pero empleando más incógnitas espaciales?
- ¿Es preferible usar métodos directos que son robustos pero poco escalables o métodos iterativos que son escalables pero sensibles a perturbaciones?
La determinación del valor de N necesario para contar con una cierta exactitud apropiada para cada método numérico no es trivial e involucra estudios paramétricos para obtener \varphi_N vs. N. Este proceso puede necesitar barrer valores de N suficientemente grandes para los cuales haya discontinuidades en la evaluación. Por ejemplo, si se debe pasar de una sola computadora a más de una por limitaciones de recursos (usualmente memoria RAM) o si se debe pasar de una infra-estructura on-premise a una basada en la nube en un eventual caso donde se necesiten más nodos (hosts) de cálculo que los disponibles.
Finalmente, como en cualquier evaluación técnico-económica, intervienen situaciones particulares más blandas relacionadas al gerenciamiento de proyectos y a la tensión de los tres vértices del triángulo alcance-costos-tiempo, como por ejemplo:
- ¿Se necesitan resultados precisos (caros y lentos) o resultados aproximados (baratos y rápidos) son suficientes?
- ¿Se prioriza disminuir los costos (como en la mayoría de los proyectos de ingeniería) o se prioriza tener resultados en poco tiempo (e.g. Proyecto Manhattan [12])?
- ¿Cómo dependen los tiempos y los costos de la infra-estructura de los recursos computacionales?
- Si es on-premise:
- amortización de hardware
- mantenimiento de hardware
- licencias de software
- administración de software
- energía eléctrica
- Si es cloud:
- alquiler de instancias
- suscripciones a servicios
- orquestación
- Si es on-premise:
- ¿Cómo son los costos asociados a la capacitación de los ingenieros que tienen que obtener \varphi con cada método numérico?
Está claro que el análisis de todas estas combinaciones están fuera del alcance de esta tesis. De todas maneras, la herramienta computacional cuya implementación describimos en detalle en el capítulo 4 permite evaluar todos estos aspectos y muchos otros ya que, en forma resumida
- Está diseñado para ser ejecutado nativamente en la nube.7
- Permite discretizar el dominio espacial utilizando mallas no estructuradas.8
- Puede correr en paralelo en una cantidad arbitraria de computadoras.9
En particular, permite a los ingenieros nucleares comparar las soluciones obtenidas con las formulaciones S_N y de difusión al resolver un mismo problema de tamaño arbitrario. De esta forma, es posible justificar ante gerencias superiores o entes regulatorios la factibilidad (o no) de encarar un proyecto para analizar un reactor nuclear con la ecuación de difusión utilizando
- datos objetivos, y
- juicio de ingeniería.
3.2 Discretización en energía
Vamos a discretizar el dominio de la energía E \in \mathbb{R} utilizando el concepto clásico de física de reactores de grupos de energías, que llevado a conceptos más generales de matemática discreta es equivalente a integrar sobre volúmenes (intervalos en \mathbb{R}) de control y utilizar el valor medio sobre cada volumen como el valor discretizado.
En efecto, tomemos el intervalo de energías [0,E_0] donde E_0 es la mayor energía esperada de un neutrón individual. Como ilustramos en la figura 3.1, dividamos dicho intervalo en G grupos (volúmenes) no necesariamente iguales, cada uno definido por energías de corte 0=E_G < E_{G-1} < \dots < E_2 < E_1 < E_0, de forma tal que el grupo g es el intervalo [E_g,E_{g-1}].
Observación. Con esta notación, el grupo número uno siempre es el de mayor energía. A medida que un neutrón va perdiendo energía, va aumentando el número de su grupo de energía.

Definición 3.4 El flujo angular \psi_g del grupo g es
\psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) = \int_{E_g}^{E_{g-1}} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \, dE
Definición 3.5 El flujo escalar \phi_g del grupo g es
\phi_g(\mathbf{x}) = \int_{E_g}^{E_{g-1}} \phi(\mathbf{x}, E) \, dE
Definición 3.6 El vector corriente \mathbf{J}_g del grupo g es
\mathbf{J}_g(\mathbf{x}) = \int_{E_g}^{E_{g-1}} \mathbf{J}(\mathbf{x},E) \, dE = \int_{E_g}^{E_{g-1}} \int_{4\pi} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \cdot \hat{\mathbf{\Omega}}\, d\hat{\mathbf{\Omega}}\, dE = \int_{4\pi} \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \cdot \hat{\mathbf{\Omega}}\, d\hat{\mathbf{\Omega}}=
Observación. Los flujos \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) y \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) no tienen las mismas unidades. La primera magnitud tiene unidades de inversa de área por inversa de ángulo sólido por inversa de energía por inversa de tiempo (por ejemplo \text{cm}^{-2} \cdot \text{eV}^{-1} \cdot \text{s}^{-1}), mientras que la segunda es un flujo integrado por lo que sus unidades son inversa de área por inversa de ángulo sólido por inversa de tiempo (por ejemplo \text{cm}^{-2} \cdot \text{s}^{-1}). La misma idea aplica a \phi(\mathbf{x}, E) y a \phi_g(\mathbf{x}).
Los tres objetivos de discretizar la energía en G grupos son
- transformar la dependencia continua del flujo angular \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) con la energía E en G funciones \psi_g(\mathbf{x},\hat{\mathbf{\Omega}}) y del flujo escalar \phi(\mathbf{x}, E) en G funciones \phi_g(\mathbf{x}),
- reemplazar las integrales sobre la variable continua E^\prime por sumatorias finitas sobre el índice g^\prime, y
- re-escribir las ecuaciones de difusión y transporte en función de los flujos de grupo (\psi_g(\mathbf{x},\hat{\mathbf{\Omega}}) en transporte y \phi_g(\mathbf{x}) en difusión)
Para ilustrar la idea, prestemos atención al término de absorción total de la ecuación de transporte \Sigma_t \cdot \psi. El objetivo es integrarlo con respecto a E entre E_g y E_{g-1} y escribirlo como el producto de una sección eficaz total asociada al grupo g por el flujo angular \psi_g de la definición 3.4:
\int_{E_g}^{E_{g-1}} \Sigma_t(\mathbf{x}, E) \cdot \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \, dE = \Sigma_{t g}(\mathbf{x}) \cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \tag{3.2}
De la misma manera, para la ecuación de difusión quisiéramos que
\int_{E_g}^{E_{g-1}} \Sigma_t(\mathbf{x}, E) \cdot \phi(\mathbf{x}, E) \, dE = \Sigma_{t g}(\mathbf{x}) \cdot \phi_g(\mathbf{x})
Según la definición 3.4, la sección eficaz total \Sigma_{t g} media en el grupo g debe ser
\Sigma_{t g}(\mathbf{x}) = \frac{\displaystyle \int_{E_g}^{E_{g-1}} \Sigma_t(\mathbf{x}, E) \cdot \phi(\mathbf{x}, E) \, dE}{\displaystyle \int_{E_g}^{E_{g-1}} \phi(\mathbf{x}, E) \, dE} con lo que no hemos ganado nada ya que llegamos a una condición tautológica donde el parámetro que necesitamos para no tener que conocer la dependencia explícita del flujo con la energía depende justamente de dicha dependencia. Sin embargo —y es ésta una de las ideas centrales del cálculo y análisis de reactores— podemos suponer que el cálculo de celda (Sección 2.5.2) es capaz de proveernos las secciones eficaz macroscópicas multigrupo para el reactor que estamos modelando de forma tal que, desde el punto de vista del cálculo de núcleo, \Sigma_{t g} y todas las demás secciones eficaces macroscópicas son distribuciones conocidas del espacio \mathbf{x}.
Para analizar la sección eficaz de \nu-fisiones, integremos el término de fisión de la ecuación de transporte entre las energías E_{g-1} y E_g e igualémoslo a una sumatoria de productos \nu\Sigma_{fg^\prime} \cdot \phi_{g^\prime}10
\int_{E_{g-1}}^{E_g} \frac{\chi(E)}{4\pi} \cdot \int_0^\infty \nu\Sigma_f(\mathbf{x},E^\prime) \cdot \phi(\mathbf{x}, E^\prime) \, dE^\prime \, dE = \frac{\chi_g}{4\pi} \cdot \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x}) \tag{3.3}
entonces
\chi_g = \int_{E_{g-1}}^{E_g} \chi(E) \, dE \tag{3.4} y
\nu\Sigma_{f g}(\mathbf{x}) = \frac{\displaystyle \int_{E^\prime_g}^{E^\prime_{g-1}} \nu\Sigma_f(\mathbf{x}, E^\prime) \cdot \phi(\mathbf{x}, E^\prime) \, dE^\prime}{\displaystyle \int_{E^\prime_g}^{E^\prime_{g-1}} \phi(\mathbf{x}, E^\prime) \, dE^\prime}
Para el término de scattering isotrópico, requerimos que
\int_{E_{g-1}}^{E_g} \frac{1}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \phi(\mathbf{x},E^\prime) \, dE^\prime \, dE = \frac{1}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x}) \tag{3.5} entonces
\Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) = \frac{\displaystyle \int_{E_{g-1}}^{E_g} \int_{E^\prime_{g-1}}^{E^\prime_g} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \phi(\mathbf{x},E^\prime) \,dE}{\displaystyle \int_{E^\prime_{g-1}}^{E^\prime_g} \phi(\mathbf{x},E^\prime) \, dE^\prime}
Observación. Necesitamos una doble integral sobre E y sobre E^\prime porque \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) es una sección eficaz diferencial y tiene unidades de inversa de longitud por inversa de ángulo sólido por inversa de energía.
Un análisis similar para el término de scattering linealmente anisótropo
\int_{E_{g-1}}^{E_g} \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \mathbf{J}(\mathbf{x},E^\prime) \, dE^\prime \, dE = \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \mathbf{J}_{g^\prime}(\mathbf{x}) \tag{3.6} arrojaría la necesidad de pesar la sección eficaz diferencial con la corriente \mathbf{J} en lugar de con el flujo escalar \phi, dejando una expresión sin sentido matemático como
\Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) = \frac{\displaystyle \int_{E_{g-1}}^{E_g} \int_{E^\prime_{g-1}}^{E^\prime_g} \Sigma_{s_1}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \mathbf{J}(\mathbf{x},E^\prime) \,dE}{\displaystyle \int_{E^\prime_{g-1}}^{E^\prime_g} \mathbf{J}(\mathbf{x},E^\prime) \, dE^\prime} a menos que tanto numerador como denominador tengan sus elementos proporcionales entre sí y la división se tome como elemento a elemento. Usualmente se desprecia la diferencia entre corriente y flujo y podemos utilizar el flujo para pesar el término de scattering anisótropo:
\Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \approx \frac{\displaystyle \int_{E_{g-1}}^{E_g} \int_{E^\prime_{g-1}}^{E^\prime_g} \Sigma_{s_1}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \phi(\mathbf{x},E^\prime) \,dE}{\displaystyle \int_{E^\prime_{g-1}}^{E^\prime_g} \phi(\mathbf{x},E^\prime) \, dE^\prime}
Integremos ahora la ecuación de transporte ecuación 2.41 con respecto a E entre E_g y E_{g-1}:
\begin{gathered} \hat{\mathbf{\Omega}}\cdot \text{grad} \left[ \int_{E_g}^{E_{g-1}} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \, dE \right] + \int_{E_g}^{E_{g-1}} \Sigma_t(\mathbf{x}, E) \cdot \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \, dE = \\ \int_{E_g}^{E_{g-1}} \frac{1}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \phi(\mathbf{x}, E^{\prime}) \, dE^\prime + \\ \int_{E_g}^{E_{g-1}} \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_1}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \mathbf{J}(\mathbf{x}, E^{\prime}) \, dE^\prime + \\ \int_{E_g}^{E_{g-1}} \frac{\chi(E)}{4\pi} \int_{0}^{\infty} \int_{4\pi} \nu\Sigma_f(\mathbf{x}, E^\prime) \cdot \phi(\mathbf{x}, E^\prime) \, dE^\prime \, dE + \int_{E_g}^{E_{g-1}} s(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \, dE \end{gathered}
Definición 3.7 Definimos la fuente de neutrones independientes del grupo g como
s_g(\mathbf{x}, \hat{\mathbf{\Omega}}) = \int_{E_g}^{E_{g-1}} s(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \, dE
Definición 3.8 Definimos el momento de orden cero de las fuentes independientes del grupo g como
s_{0g}(\mathbf{x}) = \int_{E_g}^{E_{g-1}} s_0(\mathbf{x}, E) \, dE
Teniendo en cuenta las definiciones
- 3.4 (flujo angular del grupo g)
- 3.5 (flujo escalar del grupo g)
- 3.6 (corriente del grupo g)
- 3.7 (fuente del grupo g)
y las ecuaciones
- 3.2 (ritmo de absorciones)
- 3.3 (ritmo de fisiones)
- 3.4 (espectro de fisiones)
- 3.5 (scattering isotrópico)
- 3.6 (scattering linealmente anisótropo)
obtenemos las G ecuaciones de transporte multigrupo
\begin{gathered} \hat{\mathbf{\Omega}}\cdot \text{grad} \left[ \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right] + \Sigma_{t g}(\mathbf{x}) \cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) = \frac{1}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x}) + \\ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \mathbf{J}_{g^\prime}(\mathbf{x}) + \frac{\chi_g}{4\pi} \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x}) + s_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \end{gathered} \tag{3.7} donde las incógnitas son \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) para g=1,\dots,G
Procediendo de forma análoga para la ecuación de difusión ecuación 2.62, primero integrándola con respecto a E entre E_{g-1} y E_g y luego teniendo en cuenta las definiciones
podemos obtener la ecuación de difusión multigrupo
\begin{gathered} - \text{div} \Big[ D_g(\mathbf{x}) \cdot \text{grad} \left[ \phi_g(\mathbf{x}) \right] \Big] + \Sigma_{t g}(\mathbf{x}) \cdot \phi_g(\mathbf{x}) = \\ \sum_{g^\prime = 1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x}) + \chi_g \sum_{g^\prime = 1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x})+ s_{0g}(\mathbf{x}) \end{gathered} \tag{3.8} donde ahora las incógnitas son \phi_g(\mathbf{x}) para g=1,\dots,G,
Observación. El coeficiente de difusión D_g del grupo g proviene de calcular las secciones eficaces \Sigma_{tg}, \Sigma_{st} y el coseno medio de scattering \mu_{0g} del grupo g y reemplazar la definición 2.17 por
D_g(\mathbf{x}) = \frac{1}{3 \left[ \Sigma_{tg}(\mathbf{x}) - \mu_{0g}(\mathbf{x}) \cdot \Sigma_{s_t g}(\mathbf{x}) \right]}
Observación. Matemáticamente, la aproximación multigrupo es equivalente a discretizar el dominio de la energía con un esquema de volúmenes finitos con la salvedad de que no hay operadores diferenciales con respecto a la variable E sino que el acople entre volúmenes se realiza en forma algebraica. Dicho acople no es necesariamente entre primeros vecinos solamente sino que es arbitrario, i.e. un neutrón puede pasar del grupo 1 al G, o viceversa, o de un grupo arbitrario g^\prime a otro grupo g.
Observación. Dado que en las ecuaciones multigrupo 3.7 y 3.8 la discretización es estrictamente algebraica y deliberadamente tautológica, la consistencia es teóricamente fuerte ya que el operador discretizado coincide con el operador continuo incluso para un único grupo de energías G=1. De hecho las ecuaciones multigrupo se basan solamente en definiciones. En la práctica, la consistencia depende del cálculo a nivel de celda de la Sección 2.5.2.
3.3 Discretización en ángulo
Para discretizar la dependencia espacial de la ecuación de transporte multigrupo 3.7 aplicamos el método de ordenadas discretas o S_N, discutido en la literatura tradicional de física de reactores. En esta tesis lo derivamos al integrar las ecuaciones multigrupo continuas en \hat{\mathbf{\Omega}} sobre volúmenes de control finitos como si fuese un esquema numérico basado en el método de volúmenes finitos. De hecho, en este caso, los volúmenes finitos son áreas \Delta \hat{\mathbf{\Omega}}_m discretas de la esfera unitaria donde cada una de ellas tiene asociadas
- un peso w_m
- una dirección particular \hat{\mathbf{\Omega}}_m, y
- una fracción de total de área unitaria \Delta \hat{\mathbf{\Omega}}_m/4\pi
para m=1,\dots,M. Nuevamente el acople entre volúmenes de control es algebraico y no necesariamente a primeros vecinos.
Observación. La cantidad \Delta \hat{\mathbf{\Omega}}_m es un escalar ya que representa una porción de área de la esfera unitaria alrededor del versor \hat{\mathbf{\Omega}}_m.
Teorema 3.2 (de cuadratura sobre la esfera unitaria) La integral de una función escalar f(\hat{\mathbf{\Omega}}) de cuadrado integrable sobre todas las direcciones \hat{\mathbf{\Omega}} es igual a 4\pi veces la suma de un conjunto de M pesos w_m normalizados tal que \sum w_m = 1, multiplicados por M valores medios \left\langle f(\hat{\mathbf{\Omega}})\right\rangle_m asociados a M direcciones \hat{\mathbf{\Omega}}_m donde cada una de las cuales tiene asociada también una porción \Delta \hat{\mathbf{\Omega}}_m de la esfera unitaria tal que su unión es 4\pi y su intersección es cero:
\int_{4\pi} f(\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}= 4\pi \cdot \sum_{w=1}^M w_m \cdot \left\langle f(\hat{\mathbf{\Omega}})\right\rangle_m
El peso w_m es
w_m = \frac{1}{4\pi} \cdot \int_{\Delta \hat{\mathbf{\Omega}}_m} d\hat{\mathbf{\Omega}}= \frac{\Delta \hat{\mathbf{\Omega}}_m}{4\pi}
Prueba. Comenzamos escribiendo la integral sobre 4\pi como una suma para m=1,\dots,M
\int_{4\pi} f(\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}= \sum_{m=1}^M \int_{\Delta \hat{\mathbf{\Omega}}_m} f(\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}
Multiplicamos y dividimos por \int_{\Delta \hat{\mathbf{\Omega}}_m} d\hat{\mathbf{\Omega}}= 4\pi \cdot w_m
\sum_{m=1}^M \int_{\Delta \hat{\mathbf{\Omega}}_m} f(\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}} = \sum_{m=1}^M \frac{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} f(\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}}{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} d\hat{\mathbf{\Omega}}} \cdot \int_{\Delta \hat{\mathbf{\Omega}}_m} d\hat{\mathbf{\Omega}} = \sum_{m=1}^M \frac{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} f(\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}}{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} d\hat{\mathbf{\Omega}}} \cdot 4\pi \, w_m
Si llamamos \left\langle f(\hat{\mathbf{\Omega}})\right\rangle_{\hat{\mathbf{\Omega}}_m} al valor medio de f en \Delta \hat{\mathbf{\Omega}}_m
\left\langle f(\hat{\mathbf{\Omega}})\right\rangle_{\hat{\mathbf{\Omega}}_m} = \frac{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} f(\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}}{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} d\hat{\mathbf{\Omega}}} entonces se sigue la tesis del teorema.
Definición 3.9 El flujo angular \psi_{mg} del grupo g asociado a la ordenada discreta m es igual al valor medio del flujo angular \psi_g del grupo g (definido en la definición 3.4) alrededor de la dirección \hat{\mathbf{\Omega}}_m:
\psi_{mg}(\mathbf{x}) = \left\langle \psi_g(\mathbf{x},\hat{\mathbf{\Omega}})\right\rangle_{\hat{\mathbf{\Omega}}_m} = \frac{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} \psi_g(\mathbf{x},\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}}{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} d\hat{\mathbf{\Omega}}}
Observación. Esta vez \psi_{mg} sí tiene la mismas unidades que \psi_{g}.
Corolario 3.1 La integral del flujo escalar sobre la porción \Delta \hat{\mathbf{\Omega}}_m de la esfera unitaria es 4\pi veces el producto w_m \cdot \psi_{mg}:
\int_{\Delta \hat{\mathbf{\Omega}}_m} \psi_g(\mathbf{x},\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}} = \psi_{mg}(\mathbf{x}) \cdot \Delta \hat{\mathbf{\Omega}}_m = 4\pi \cdot w_m \cdot \psi_{mg}(\mathbf{x})
Corolario 3.2 El flujo escalar \phi_g del grupo g es igual a
\phi_g(\mathbf{x}) = \int_{4\pi} \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}= 4\pi \sum_{m=1}^M w_m \cdot \psi_{mg}(\mathbf{x})
Re-escribamos primero la ecuación 3.7 de transporte multigrupo \tag{\ref{eq-transportemultigrupo}} \begin{gathered} \hat{\mathbf{\Omega}}\cdot \text{grad} \left[ \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right] + \Sigma_{t g}(\mathbf{x}) \cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) = \frac{1}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x}) + \\ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \mathbf{J}_{g^\prime}(\mathbf{x}) + \frac{\chi_g}{4\pi} \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x}) + s_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \end{gathered}
en función de los flujos angulares \psi_{mg} usando la definición 3.9 y explicitando el termino de la corriente como la integral del producto \psi_{g^\prime} \cdot \hat{\mathbf{\Omega}} según la definición 3.6
\begin{gathered} \hat{\mathbf{\Omega}}\cdot \text{grad} \left[ \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right] + \Sigma_{t g}(\mathbf{x}) \cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) = \\ \frac{1}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot 4\pi \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) + \\ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} \int_{\hat{\mathbf{\Omega}}_{m^\prime}} \psi_{g^\prime}(\mathbf{x},\hat{\mathbf{\Omega}}) \cdot \hat{\mathbf{\Omega}}\, d\hat{\mathbf{\Omega}}+\\ \frac{\chi_g}{4\pi} \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x})\cdot 4\pi \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) + s_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \end{gathered}
Ahora cancelamos los factores 4\pi en los términos de scattering lineal y fisión, integramos todos los términos con respecto a \hat{\mathbf{\Omega}} sobre \Delta \hat{\mathbf{\Omega}}_m y los analizamos uno por uno:
\begin{gathered} \underbrace{\int_{\hat{\mathbf{\Omega}}_m} \left\{ \hat{\mathbf{\Omega}}\cdot \text{grad} \left[ \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right] \right\} \, d\hat{\mathbf{\Omega}}}_\text{advección} + \underbrace{\int_{\hat{\mathbf{\Omega}}_m} \left\{ \Sigma_{t g}(\mathbf{x}) \cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right\} \, d\hat{\mathbf{\Omega}}}_\text{absorción total} = \\ \underbrace{\int_{\hat{\mathbf{\Omega}}_m} \left\{ \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \right\} \, d\hat{\mathbf{\Omega}}}_\text{scattering isotrópico} + \\ \underbrace{\int_{\hat{\mathbf{\Omega}}_m} \left\{ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} \int_{\hat{\mathbf{\Omega}}_{m^\prime}} \psi_{g^\prime}(\mathbf{x},\hat{\mathbf{\Omega}}^\prime) \cdot \hat{\mathbf{\Omega}}^\prime \, d\hat{\mathbf{\Omega}}^\prime \right\} \, d\hat{\mathbf{\Omega}}}_\text{scattering linealmente anisótropo} +\\ \underbrace{\int_{\hat{\mathbf{\Omega}}_m} \left\{ \chi_g \cdot \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \right\} \, d\hat{\mathbf{\Omega}}}_\text{fisión} + \underbrace{\int_{\hat{\mathbf{\Omega}}_m} \left\{ s_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right\} \, d\hat{\mathbf{\Omega}}}_\text{fuentes independientes} \end{gathered} \tag{3.9}
Comencemos por el termino de advección, revirtiendo el teorema 2.9
\begin{aligned} \int_{\hat{\mathbf{\Omega}}_m} \left\{ \hat{\mathbf{\Omega}}\cdot \text{grad} \left[ \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right] \right\} \, d\hat{\mathbf{\Omega}} &= \int_{\hat{\mathbf{\Omega}}_m} \text{div} \left[ \hat{\mathbf{\Omega}}\cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right] \, d\hat{\mathbf{\Omega}} \\ &= \text{div} \left[ \int_{\hat{\mathbf{\Omega}}_m} \hat{\mathbf{\Omega}}\cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}\right] \end{aligned}
Prestemos atención a la integral. Supongamos que el flujo angular es constante a trozos11 dentro de cada área \Delta \hat{\mathbf{\Omega}}_m. Entonces este valor constante es igual al valor medio de \psi en \Delta \hat{\mathbf{\Omega}}_m
\psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) = \left\langle \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right\rangle_{\hat{\mathbf{\Omega}}_m} = \psi_{mg}(\mathbf{x}) \quad \text{si $\hat{\mathbf{\Omega}}\in \Delta \hat{\mathbf{\Omega}}_m$}
En estas condiciones, \psi puede salir de la integral
\int_{\hat{\mathbf{\Omega}}_m} \hat{\mathbf{\Omega}}\cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}} \approx \psi_{mg}(\mathbf{x}) \cdot \int_{\hat{\mathbf{\Omega}}_m} \hat{\mathbf{\Omega}}\, d\hat{\mathbf{\Omega}}
Definición 3.10 Llamamos \hat{\mathbf{\Omega}}_m a la dirección que resulta ser el valor medio \left\langle \hat{\mathbf{\Omega}}\right\rangle_{\hat{\mathbf{\Omega}}_m} de todas las direcciones integradas en el área \Delta \hat{\mathbf{\Omega}}_m sobre la esfera unitaria, es decir
\hat{\mathbf{\Omega}}_m = \left\langle \hat{\mathbf{\Omega}}\right\rangle_{\hat{\mathbf{\Omega}}_m} = \frac{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} \hat{\mathbf{\Omega}}\, d\hat{\mathbf{\Omega}}}{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} d\hat{\mathbf{\Omega}}}
Corolario 3.3 La integral del versor \hat{\mathbf{\Omega}} sobre la fracción \Delta \hat{\mathbf{\Omega}}_m de la esfera unitaria es igual al producto de \hat{\mathbf{\Omega}}_m por \Delta \hat{\mathbf{\Omega}}_m:
\int_{\Delta \hat{\mathbf{\Omega}}_m} \hat{\mathbf{\Omega}}\, d\hat{\mathbf{\Omega}} = \hat{\mathbf{\Omega}}_m \cdot \Delta \hat{\mathbf{\Omega}}_m
Corolario 3.4 La integral del producto del versor \hat{\mathbf{\Omega}} con el flujo angular del grupo g sobre \Delta \hat{\mathbf{\Omega}}_m es aproximadamente igual al producto \psi_{mg} \cdot \Delta \hat{\mathbf{\Omega}}_m:
\int_{\hat{\mathbf{\Omega}}_m} \hat{\mathbf{\Omega}}\cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}} \approx \hat{\mathbf{\Omega}}_m \cdot \psi_{mg}(\mathbf{x}) \cdot \Delta \hat{\mathbf{\Omega}}_m
Podemos volver a aplicar el teorema 2.9 para escribir el término de advección como
\begin{aligned} \text{div} \left[ \int_{\hat{\mathbf{\Omega}}_m} \hat{\mathbf{\Omega}}\cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}\right] & \approx \text{div} \left[ \hat{\mathbf{\Omega}}_m \cdot \psi_{mg}(\mathbf{x}) \cdot \Delta \hat{\mathbf{\Omega}}_m \right] \\ & \approx \hat{\mathbf{\Omega}}_m \cdot \text{grad} \left[ \psi_{mg}(\mathbf{x}) \right] \cdot \Delta \hat{\mathbf{\Omega}}_m \\ \end{aligned} \tag{3.10}
Pasemos ahora al término de absorciones totales de la ecuación 3.9. La sección eficaz no depende de \hat{\mathbf{\Omega}} por lo que puede salir fuera de la integral
\int_{\hat{\mathbf{\Omega}}_m} \left\{ \Sigma_{t g}(\mathbf{x}) \cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right\} \, d\hat{\mathbf{\Omega}}= \Sigma_{t g}(\mathbf{x}) \cdot \int_{\hat{\mathbf{\Omega}}_m} \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}
Por el corolario 3.1 la última integral es \psi_{mg} \cdot \Delta \hat{\mathbf{\Omega}}_m, entonces
\int_{\hat{\mathbf{\Omega}}_m} \left[ \Sigma_{t g}(\mathbf{x}) \cdot \psi_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right] \, d\hat{\mathbf{\Omega}}= \left[ \Sigma_{t g}(\mathbf{x}) \cdot \psi_{mg}(\mathbf{x}) \right] \cdot \Delta \hat{\mathbf{\Omega}}_m \tag{3.11}
El término de scattering isotrópico queda
\int_{\hat{\mathbf{\Omega}}_m} \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \, d\hat{\mathbf{\Omega}} = \left[ \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \right] \cdot \Delta \hat{\mathbf{\Omega}}_m \tag{3.12} ya que el integrando no depende de \hat{\mathbf{\Omega}}.
El integrando del término de scattering linealmente anisótropo sí depende de \hat{\mathbf{\Omega}}.
\int_{\hat{\mathbf{\Omega}}_m} \left[ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} \int_{\hat{\mathbf{\Omega}}_{m^\prime}} \psi_{g^\prime}(\mathbf{x},\hat{\mathbf{\Omega}}^\prime) \cdot \hat{\mathbf{\Omega}}^\prime \, d\hat{\mathbf{\Omega}}^\prime \right] \, d\hat{\mathbf{\Omega}}
Primero notamos que el corolario 3.4 nos indica, de manera aproximada, el resultado de la integral sobre \hat{\mathbf{\Omega}}_{m^\prime}: \hat{\mathbf{\Omega}}_{m^\prime} \psi_{m^\prime g^\prime} \Delta\hat{\mathbf{\Omega}}_{m^\prime}. A su vez, \Delta\hat{\mathbf{\Omega}}_{m^\prime} = 4\pi w_{m^\prime}, por lo que
\begin{gathered} \int_{\hat{\mathbf{\Omega}}_m} \left[ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} 4\pi \cdot w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \cdot \hat{\mathbf{\Omega}}_{m^\prime} \right] \, d\hat{\mathbf{\Omega}} = \\ 3 \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \cdot \hat{\mathbf{\Omega}}_{m^\prime} \int_{\hat{\mathbf{\Omega}}_m} \hat{\mathbf{\Omega}}\, d\hat{\mathbf{\Omega}} \end{gathered}
Una vez mas, la integral sobre \hat{\mathbf{\Omega}}_m ya la hemos resuelto (exactamente) en el corolario 3.3, y es igual a \hat{\mathbf{\Omega}}_m \cdot \Delta \hat{\mathbf{\Omega}}_m. Entonces el término de scattering linealmente anisótropo es aproximadamente igual a \begin{gathered} \int_{\hat{\mathbf{\Omega}}_m} \left[ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} \int_{\hat{\mathbf{\Omega}}_{m^\prime}} \psi_{g^\prime}(\mathbf{x},\hat{\mathbf{\Omega}}^\prime) \cdot \hat{\mathbf{\Omega}}^\prime \, d\hat{\mathbf{\Omega}}^\prime \right] \, d\hat{\mathbf{\Omega}} \approx \\ \left[ 3 \cdot \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \left( \hat{\mathbf{\Omega}}_{m} \cdot \hat{\mathbf{\Omega}}_{m^\prime} \right) \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \right] \cdot \Delta \hat{\mathbf{\Omega}}_m \end{gathered} \tag{3.13}
El término de fisiones es similar al de scattering isotrópico en el sentido de que el integrando no depende de \hat{\mathbf{\Omega}} entonces su integral sobre \Delta \hat{\mathbf{\Omega}}_m es directamente
\int_{\hat{\mathbf{\Omega}}_m} \chi_g \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \, d\hat{\mathbf{\Omega}} = \left[ \chi_g \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \right] \cdot \Delta \hat{\mathbf{\Omega}}_m \tag{3.14}
Para completar el análisis de la ecuación 3.9, en el término de las fuentes independientes usamos el concepto de valor medio
\int_{\hat{\mathbf{\Omega}}_m} s_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}} = \left\langle s_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \right\rangle_{\hat{\mathbf{\Omega}}_m} \cdot \Delta \hat{\mathbf{\Omega}}
Definición 3.11 En forma análoga a la definición 3.9, definimos a la fuente independiente del grupo g en la dirección m como
s_{mg}(\mathbf{x}) = \left\langle s(\mathbf{x},\hat{\mathbf{\Omega}})\right\rangle_{\hat{\mathbf{\Omega}}_m} = \frac{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} s_g(\mathbf{x},\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}}{ \displaystyle \int_{\Delta \hat{\mathbf{\Omega}}_m} d\hat{\mathbf{\Omega}}}
El término de fuentes independientes es entonces
\int_{\hat{\mathbf{\Omega}}_m} s_g(\mathbf{x}, \hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}} = s_{mg}(\mathbf{x}) \cdot \Delta \hat{\mathbf{\Omega}}_m \tag{3.15}
Juntemos ahora las ecuaciones
- 3.10 (advección)
- 3.11 (absorciones)
- 3.12 (scattering isotrópico)
- 3.13 (scattering linealmente anisótropo)
- 3.14 (fisiones)
- 3.15 (fuentes independientes)
para re-escribir la ecuación 3.9 como
\begin{gathered} \left[ \hat{\mathbf{\Omega}}_m \cdot \text{grad} \left[ \psi_{mg}(\mathbf{x}) \right] \right] \cdot \Delta \hat{\mathbf{\Omega}}_m + \left[ \Sigma_{t g}(\mathbf{x}) \cdot \psi_{mg}(\mathbf{x}) \right] \cdot \Delta \hat{\mathbf{\Omega}}_m = \\ \left[ \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \right] \cdot \Delta \hat{\mathbf{\Omega}}_m + \\ \left[ 3 \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \left( \hat{\mathbf{\Omega}}_{m} \cdot \hat{\mathbf{\Omega}}_{m^\prime} \right) \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \right] \cdot \Delta \hat{\mathbf{\Omega}}_m + \\ \left[ \chi_g \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \sum_{m^\prime=1} w_{m^\prime} \cdot \psi_{m^\prime g^\prime}(\mathbf{x}) \right] \cdot \Delta \hat{\mathbf{\Omega}}_m + s_{mg}(\mathbf{x}) \cdot \Delta \hat{\mathbf{\Omega}}_m \end{gathered}
Dividiendo ambos miembros por \Delta \hat{\mathbf{\Omega}} obtenemos las MG ecuaciones diferenciales de transporte en G grupos de energías y M direcciones angulares, según la discretización angular denominada en la literatura “ordenadas discretas”
\begin{gathered} \hat{\mathbf{\Omega}}_m \cdot \text{grad} \left[ \psi_{mg}(\mathbf{x}) \right] + \Sigma_{t g}(\mathbf{x}) \cdot \psi_{mg}(\mathbf{x}) = \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \sum_{m^\prime=1} w_{m^\prime} \psi_{m^\prime g^\prime}(\mathbf{x}) + \\ 3 \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \sum_{m^\prime=1} w_{m^\prime} \left( \hat{\mathbf{\Omega}}_{m} \cdot \hat{\mathbf{\Omega}}_{m^\prime} \right) \psi_{m^\prime g^\prime}(\mathbf{x}) + \chi_g \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \sum_{m^\prime=1} w_{m^\prime} \psi_{m^\prime g^\prime}(\mathbf{x}) + s_{mg}(\mathbf{x}) \end{gathered} \tag{3.16}
Observación. El único operador diferencial que aparece en la ecuación 3.16 es el gradiente espacial del flujo angular \psi_{mg} del grupo g en la dirección m en el término de advección.
Observación. Todos los operadores integrales que estaban presentes en la ecuación 2.41 han sido reemplazados por sumatorias finitas.
Observación. La única aproximación numérica que tuvimos que hacer para obtener la ecuación 3.16 a partir de la ecuación 3.7 fue suponer que el flujo angular \psi_g es uniforme a trozos en cada segmento de área \Delta \hat{\mathbf{\Omega}}_m en los términos de
- absorciones totales (ecuación 3.11), y
- scattering linealmente anisótropo (ecuación 3.13).
Por ejemplo, la figura 3.2 ilustra un caso en el que cada octante de la esfera unitaria está dividido en tres áreas iguales, dando lugar a M = 3 \times 8 = 24 direcciones. En cada una de las áreas mostradas, asumimos que el flujo angular \psi(\mathbf{x},\hat{\mathbf{\Omega}}) es uniformemente igual a \psi_{mg}(\mathbf{x}), siendo \mathbf{x} en este caso la posición del centro de la esfera unidad. Esta suposición es usual en los esquemas basados en el método de volúmenes finitos.
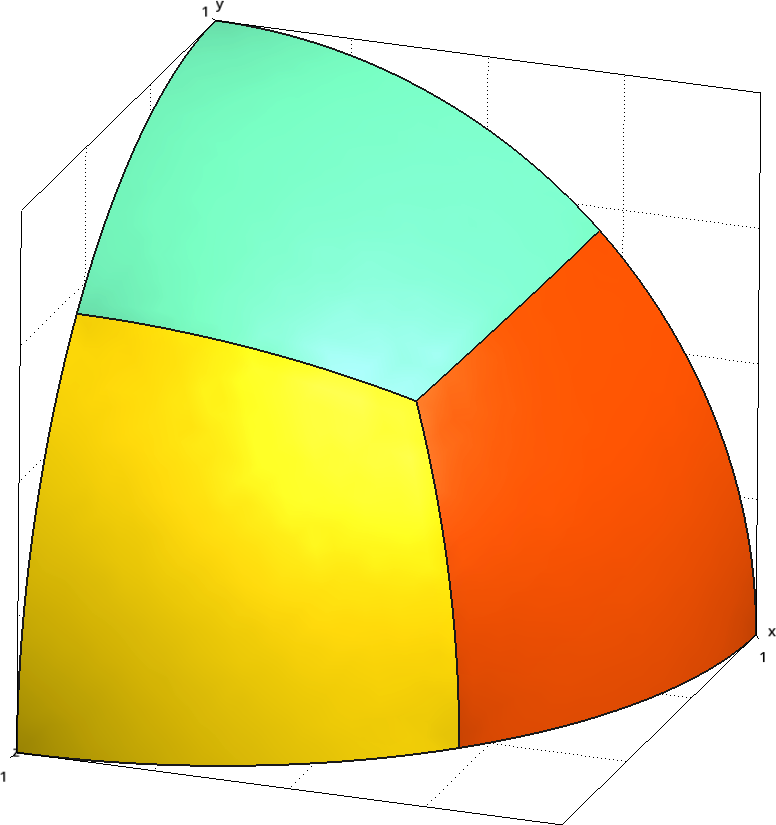
Observación. El esquema numérico es consistente ya que en el límite \Delta \hat{\mathbf{\Omega}}_m \rightarrow d\hat{\mathbf{\Omega}}_m la suposición es exacta y el operador discretizado coincide con el operador continuo.
3.3.1 Conjuntos de cuadratura
Para completar el método de las ordenadas discretas debemos especificar M pares de direcciones y pesos (\hat{\mathbf{\Omega}}_m, w_m) para m=1,\dots,M. En tres dimensiones, si utilizamos M direcciones tales que
M = N\cdot(N+2) \tag{3.17} decimos que estamos implementando el método de ordenadas discretas S_N. Esta relación numérica entre N y M es histórica y en esta tesis la mantenemos.
Las direcciones \hat{\mathbf{\Omega}}_m = [\hat{\Omega}_{mx} \, \hat{\Omega}_{my} \, \hat{\Omega}_{mz}]^T deben ser versores unitarios tales que
\hat{\Omega}_{mx}^2 + \hat{\Omega}_{my}^2 + \hat{\Omega}_{mz}^2 = 1 \tag{3.18} y para poder aplicar el teorema 3.2, los pesos w_m deben estar normalizados a uno, es decir
\sum_{m=1}^M w_m = 1
Existen varias maneras de elegir los M pares de forma tal de cumplir estas dos condiciones. En primer lugar, para poder poner condiciones de contorno de simetría en planos paralelos a los tres planos coordinados x-y, x-z e y-z requerimos que si la dirección \hat{\mathbf{\Omega}}= [\hat{\Omega}_{x} \, \hat{\Omega}_{y} \, \hat{\Omega}_{z}]^T con \hat{\Omega}_{x} > 0, \hat{\Omega}_{y} >0 y \hat{\Omega}_{z} > 0 pertenece al conjunto de cuadratura, entonces también tienen que estar las siguientes siete direcciones
\begin{aligned} \begin{bmatrix} +\hat{\Omega}_{x} & +\hat{\Omega}_{y} & -\hat{\Omega}_{z} \end{bmatrix}^T \\ \begin{bmatrix} +\hat{\Omega}_{x} & -\hat{\Omega}_{y} & +\hat{\Omega}_{z} \end{bmatrix}^T \\ \begin{bmatrix} +\hat{\Omega}_{x} & -\hat{\Omega}_{y} & -\hat{\Omega}_{z} \end{bmatrix}^T \\ \begin{bmatrix} -\hat{\Omega}_{x} & +\hat{\Omega}_{y} & +\hat{\Omega}_{z} \end{bmatrix}^T \\ \begin{bmatrix} -\hat{\Omega}_{x} & +\hat{\Omega}_{y} & -\hat{\Omega}_{z} \end{bmatrix}^T \\ \begin{bmatrix} -\hat{\Omega}_{x} & -\hat{\Omega}_{y} & +\hat{\Omega}_{z} \end{bmatrix}^T \\ \begin{bmatrix} -\hat{\Omega}_{x} & -\hat{\Omega}_{y} & -\hat{\Omega}_{z} \end{bmatrix}^T \\ \end{aligned}
Luego es suficiente definir las N(N+2)/8 direcciones del primero de los ocho octantes y luego permutar los signos para obtener las direcciones correspondientes a los otros siete octantes. En este trabajo utilizamos la cuadratura de nivel simétrico [9] o de simetría completa [14] en la que las direcciones son simétricas en cada octante. Consiste en tomar tres cosenos directores \mu_i, \mu_j y \mu_k de un conjunto de N/2 valores positivos y permutarlos de todas las maneras posibles para obtener N(N+2)/8 combinaciones como ilustramos en la figura 3.3 y continuamos discutiendo a continuación.






Teorema 3.3 En la cuadratura de nivel simétrico, no todos los N/2 posibles cosenos directores son independientes. Para S_2 hay una única dirección posible. Para N >2 sólo uno de los cosenos directores es independiente. El resto de los valores depende del primero.
Prueba. Para N=2 hay una única dirección posible en cada octante que proviene de un único cosenos director \mu_1 ya que N/2=1. Luego \hat{\mathbf{\Omega}}_1 = [\mu_1 ~ \mu_1 ~ \mu_1]^T. Para preservar la condición de normalización, debe ser \mu_1 = 1/\sqrt{3}.
Para N>2, sean \mu_1 \le \mu_2 \le \dots < \mu_{N/2} los posibles cosenos directores del conjunto. Supongamos que para la dirección m tenemos \hat{\Omega}_{mx} = \mu_i, \hat{\Omega}_{my} = \mu_j y \hat{\Omega}_{mz} = \mu_k. Entonces, por el requerimiento de normalización de la ecuación 3.18 debemos tener
\mu_i^2 + \mu_j^2 + \mu_k^2 = 1 \tag{3.19}
Tomemos ahora otra dirección diferente m^\prime pero manteniendo el primer componente \hat{\Omega}_{m^\prime x} = \mu_i y haciendo que \hat{\Omega}_{m^\prime y} = \mu_{j+1}. Para poder satisfacer la ecuación 3.19, debido a que \mu_{j+1}>\mu_{j} entonces \hat{\Omega}_{m^\prime z} = \mu_{k-1} ya que \mu_{k-1}<\mu_k. Entonces
\mu_i^2 + \mu_{j+1}^2 + \mu_{k-1}^2 = 1 \tag{3.20}
De las ecuaciones 3.19 y 3.20 obtenemos
\mu_{j+1}^2 - \mu_{j} = \mu_{k}^2 - \mu_{k-1}^2
Como esta condición debe cumplirse para todo j y para todo k, entonces
\mu_i^2 = \mu_{i-1} + C para todo 1 < i \leq N/2, con C una constante a determinar. Luego el i-ésimo coseno director es
\mu_i^2 = \mu_{1} + C \cdot (i-1)
Si tomamos \hat{\Omega}_{mx} = \hat{\Omega}_{my} = \mu_1 y \hat{\Omega}_{mz}=\mu_{N/2}, por la condición de magnitud unitaria debe ser
2\mu_1^2 + \mu_{N/2}^2 = 1 de donde podemos determinar la constante C como
C = \frac{2 \cdot (1 - 3\mu_1^2)}{N-2}
Finalmente, una vez seleccionado el coseno director \mu_1, podemos calcular el resto de los N/2-1 valores como
\mu_{i} = \sqrt{\mu_1^2 + (2 - 6\mu_1^2) \cdot \frac{(i-1)}{N-2}} para i=2,\dots,N/2.
| S_2 | |
S_4 | |
| S_6 | |
S_8 | |
| S_{10} | |
S_{12} | |
| S_{14} | |
S_{16} | |
Observación. Si el primer coseno director \mu_1 es cercano a cero, las direcciones tienden a formar un cluster alrededor de los polos. Si el primer coseno director \mu_1 es cercano a 1/\sqrt{3}, las direcciones tienden a formar un cluster alrededor del centro de cada octante.
Si miráramos el octante desde la dirección [1/\sqrt{3}~1/\sqrt{3}~1/\sqrt{3}]^T como en la segunda columna de la figura 3.3 y le asignáramos el mismo entero a cada dirección que sea una permutación de los mismos tres cosenos directores, veríamos lo que indica la tabla 3.1. Las condiciones de simetría requieren que los pesos w_m y w_{m^\prime} asociados a dos direcciones \boldsymbol{\hat\Omega}_m y \boldsymbol{\hat\Omega}_{m^\prime} cuyos cosenos directores son permutaciones entre sí deban ser iguales. Por lo tanto, los enteros de la tabla 3.1 terminan indicando el índice del peso a utilizar.
Observación. Para N=2 el triángulo de la tabla 3.1 tiene N/2=1 fila. Para cada nuevo N, se agrega una fila con N/2 nuevas direcciones. Entonces la cantidad de direcciones en un octante para S_N es
\frac{\frac{N}{2} \left( \frac{N}{2}+1 \right) }{2} = \frac{\frac{1}{2} \cdot N \cdot \frac{1}{2} \left( N+2 \right) }{2} = \frac{N \cdot (N+2)}{8} de donde sigue la ecuación 3.17.
La elección de los w_m debe ser tal que la cuadratura
\int_{4\pi} f(\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}\approx 4\pi \cdot \sum_{w=1}^M w_m \cdot \left\langle f(\hat{\mathbf{\Omega}})\right\rangle_m del teorema teorema 3.2 arroje los resultados más precisos posibles en la ecuación de transporte de neutrones. En este sentido, dos condiciones importantes son las siguientes.
Dado que la corriente neta se aproxima como
\mathbf{J}_g(\mathbf{x}) \approx \sum_{m=1}^M w_m \cdot \hat{\mathbf{\Omega}}_m \cdot \phi_{mg}(\mathbf{x}) entonces para poder recuperar una corriente neta igual a cero para un flujo angular uniforme debemos tener
\sum_{m=1}^M w_m \cdot \hat{\mathbf{\Omega}}_m \cdot = 0
Para poder recuperar el resultado
\psi_{mg}(\mathbf{x}) \approx \frac{1}{4\pi} \phi_{mg}(\mathbf{x}) + 3 \cdot \hat{\mathbf{\Omega}}_m \cdot \mathbf{J}_{mg}(\mathbf{x}) entonces
\sum_{m=1}^M w_m \cdot \hat{\mathbf{\Omega}}_m^2 \cdot = \frac{1}{3}
Observación. Para extender las N(N+2)/8 direcciones a los demás cuadrantes, podemos notar que si asignamos un índice n a cada uno de los ocho octantes de la siguiente manera:
- x>0, y>0, z>0
- x<0, y>0, z>0
- x>0, y<0, z>0
- x<0, y<0, z>0
- x>0, y>0, z<0
- x<0, y>0, z<0
- x>0, y<0, z<0
- x<0, y<0, z<0
entonces el desarrollo binario del índice n tiene tres bits y éstos indican si hubo un cambio de signo o no en cada uno de los tres ejes con respecto al primer cuadrante, que corresponde a n=0. De esta manera, es posible generar las direcciones \boldsymbol{\hat{\Omega}}_m para m=N(N+2)/8+1, N(N+2) a partir de las direcciones del primer cuadrante \boldsymbol{\hat{\Omega}}_j para j=1,N(N+2)/8 con el siguiente algoritmo
donde
- el símbolo “et”
&indica el operador binarioANDy - el signo de pregunta
?el operador ternario de decisión.
El cálculo detallado de los pesos está fuera del alcance de esta tesis. La herramienta computacional tiene cargados el primer coseno director de cada N y los pesos reportados en las referencias [9], [14]. Consultar el código fuente de la implementación descripta en el capítulo 4 para ver los detalles algorítmicos y numéricos.
3.3.1.1 Dos dimensiones
El caso bidimensional en realidad es un problema en tres dimensiones pero sin dependencia de los parámetros del problema en una de las variables espaciales, digamos z. De esta manera, el dominio U \in \mathbb{R}^2 de la geometría está definido sólo sobre el plano x-y y las direcciones de vuelo \hat{\mathbf{\Omega}} de los neutrones son simétricas con respecto a este plano ya que por cada dirección \hat{\mathbf{\Omega}}= [\hat{\Omega}_x \, \hat{\Omega}_y \, \hat{\Omega}_z] con \hat{\Omega}_z>0 hay una dirección simétrica \hat{\mathbf{\Omega}}^\prime= [\hat{\Omega}_x \, \hat{\Omega}_y \, -\hat{\Omega}_z] (figura 3.4). Luego, las posibles direcciones se reducen a la mitad, es decir N(N+2)/2.

Como la derivada espacial del flujo angular con respecto a z es cero entonces por un lado podemos escribir el término de transporte en la ecuación 3.16 como
\hat{\Omega}_{mx} \cdot \frac{\partial{\psi_{mg}}(x,y)}{\partial x} + \hat{\Omega}_{my} \cdot \frac{\partial{\psi_{mg}(x,y)}}{\partial y} donde ahora m=1,\dots,M = N(N+2)/2. La componente {\Omega}_{mz} no aparece explícitamente en las ecuaciones pero sí lo hace implícitamente en la elección de las direcciones, ya que sigue siendo válida la discusión de la sección anterior. Esto implica que en cada cuadrante tenemos nuevamente N(N+2)/8 direcciones posibles, que luego debemos rotar para obtener las M direcciones en los cuatro cuadrantes. Dado que por un lado los pesos deben estar normalizados a uno y por otro para cada dirección con \hat{\Omega}_z>0 hay otra dirección simétrica con \hat{\Omega}_z<0, entonces el conjunto de cuadraturas de nivel simétrico para el primer cuadrante de un dominio de dos dimensiones consiste en las mismas N(N+2)/8 direcciones correspondientes a tres dimensiones.
3.3.1.2 Una dimensión
El caso unidimensional es radicalmente diferente a los otros dos. Si tomamos al eje x como la dirección de dependencia espacial, las posibles direcciones de viaje pueden depender sólo del ángulo cenital \theta ya que la simetría implica que todas las posibles direcciones azimutales con respecto al eje x son igualmente posibles.

El término de transporte es ahora entonces
\hat{\Omega}_{mx} \cdot \frac{\partial{\psi_{mg}}(x)}{\partial x}
El hecho de que no una sino dos componentes de \hat{\mathbf{\Omega}} no aparezcan explícitamente relaja mucho más las condiciones para la elección de las M=N direcciones. En efecto, la única condición es simetría completa entre el semieje x>0 y el semieje x<0, lo que nos deja con N/2 direcciones en cada semieje, todas ellas libres e independientes.
Para seleccionar las N/2 direcciones y sus pesos asociados, notamos que en una dimensión
\int_{4\pi} f(\hat{\mathbf{\Omega}}) \, d\hat{\mathbf{\Omega}}= 2\pi \int_{-1}^{1} f(\hat{\Omega}_x) \, d\hat{\Omega}_x \simeq 2\pi \sum_{m=1}^N w_m \cdot f_m = 4\pi \sum_{m=1}^N \frac{w_m}{2} \cdot f_m = 4\pi \sum_{m=1}^N w_m \cdot f_m \tag{3.21}
Si los puntos \hat{\Omega}_{xm} y los pesos w_m=2\cdot w_m son los asociados a la integración de Gauss y f(\hat{\Omega}_x) es un polinomio de orden 2N-1 o menos, entonces la integración es exacta. En la tabla tabla 3.2 mostramos el conjunto de cuadraturas utilizadas para una dimensión, que contiene esencialmente las abscisas y los pesos de la cuadratura de Gauss.
| m | \hat{\Omega}_{mx} | 2 \cdot w_m | |
|---|---|---|---|
| S_2 | 1 | \sqrt{\frac{1}{3}} | 1 |
| S_4 | 1 | \sqrt{\frac{3}{7}-\frac{2}{7}\sqrt{\frac{6}{5}}} | 0.6521451549 |
| 2 | \sqrt{\frac{3}{7}+\frac{2}{7}\sqrt{\frac{6}{5}}} | 0.3478548451 | |
| S_6 | 1 | 0.2386191860 | 0.4679139346 |
| 2 | 0.6612093864 | 0.3607615730 | |
| 3 | 0.9324695142 | 0.1713244924 | |
| S_8 | 1 | 0.1834346424 | 0.3626837834 |
| 2 | 0.5255324099 | 0.5255324099 | |
| 3 | 0.7966664774 | 0.2223810344 | |
| 4 | 0.9602898564 | 0.1012285363 |
Tabla 3.2: Conjuntos de cuadratura para problemas unidimensionales. Las direcciones \hat{\Omega}_{mx} coinciden con las abscisas de la cuadratura de Gauss. Los pesos w_m de ordenadas discretas son la mitad de los pesos w_m de la cuadratura de Gauss. Las direcciones m=N/2+1,\dots,N no se muestran pero se obtienen como \hat{\Omega}_{N/2+m \, x} = -\hat{\Omega}_{mx} y w_{N/2+m} = w_m.
3.4 Discretización en espacio
Hasta el momento, tenemos por un lado las G ecuaciones de difusión multigrupo
\tag{\ref{eq-difusionmultigrupo}} \begin{gathered} - \text{div} \Big[ D_g(\mathbf{x}) \cdot \text{grad} \left[ \phi_g(\mathbf{x}) \right] \Big] + \Sigma_{t g}(\mathbf{x}) \cdot \phi_g(\mathbf{x}) = \\ \sum_{g^\prime = 1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x}) + \chi_g \sum_{g^\prime = 1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x})+ s_{0g}(\mathbf{x}) \end{gathered} y las MG ecuaciones de transporte S_N multigrupo
\tag{\ref{eq-transporte-sn}} \begin{gathered} \hat{\mathbf{\Omega}}_m \cdot \text{grad} \left[ \psi_{mg}(\mathbf{x}) \right] + \Sigma_{t g}(\mathbf{x}) \cdot \psi_{mg}(\mathbf{x}) = \sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \sum_{m^\prime=1} w_{m^\prime} \psi_{m^\prime g^\prime}(\mathbf{x}) + \\ 3 \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \sum_{m^\prime=1} w_{m^\prime} \left( \hat{\mathbf{\Omega}}_{m} \cdot \hat{\mathbf{\Omega}}_{m^\prime} \right) \psi_{m^\prime g^\prime}(\mathbf{x}) + \chi_g \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \sum_{m^\prime=1} w_{m^\prime} \psi_{m^\prime g^\prime}(\mathbf{x}) + s_{mg}(\mathbf{x}) \end{gathered} en las que las incógnitas \phi_g y \psi_{mg} dependen solamente del espacio \mathbf{x}. En esta sección empleamos el método de elementos finitos [16] para discretizar la variable independiente espacial y obtener finalmente un sistema de ecuaciones algebraicas que nos permita resolver neutrónica a nivel de núcleo en forma numérica con una (o más) computadora(s) digital(es).
Existe una gran cantidad de teoría matemática detrás del método de elementos finitos para resolver ecuaciones diferenciales a partir de formulaciones débiles o variacionales. Esencialmente el grueso de la literatura teórica [3], [8], [11] se centra en probar
- que la formulación débil (definición 3.13) de una ecuación diferencial es formalmente correcta con respecto a derivabilidad e integrabilidad en el sentido de distribuciones sobre espacios de Hilbert,
- que soluciones continuas pero no necesariamente diferenciables en a lo más un sub-espacio de medida cero tienen sentido matemático, y
- que el esquema numérico es consistente (definición 3.2), estable (definición 3.3) y convergente (definición 3.1).
De la misma manera que el capítulo 2, esencialmente repetimos teoría matemática ya conocida a partir de diferentes fuente pero “digerida” a lo Séneca de forma tal de unificar nomenclaturas y criterios, en este hacemos lo mismo por cuestiones de consistencia. Mostramos algunos resultados conocidos y derivamos con algún cierto nivel de detalle razonable (teniendo en cuenta que es ésta una tesis de Ingeniería y no de Matemática) el problema de aproximación de Galerkin a partir de la formulación débil de un problema en derivadas parciales. Dejamos la derivación completa incluyendo la teoría de análisis funcional necesaria para demostrar completamente todos los resultados del método de elementos finitos en las referencias [3], [7], [11]. En la monografía [15] escrita durante el plan de formación de este doctorado se muestra una derivación de la formulación en elementos finitos de la ecuación de difusión multigrupo de forma menos formal pero más intuitiva. Incluso se comparan los resultados numéricos obtenidos con dicha formulación con los obtenidos con una formulación basada en volúmenes finitos [4].
Proposición 3.1 Si se pudiera intercambiar en toda la literatura existente (y en las clases, seminarios, conferencias, etc.) la palabra “elementos” por “volúmenes” (¿tal vez con sed siguiendo la filosofía del Apéndice C?) nadie notaría la diferencia. Ver la referencia [10] y sus doscientas ochenta referencias para la historia detrás del “método de elementos finitos”.
Comenzamos ilustrando la aplicación el método de elementos finitos a un operador elíptico escalar, en particular a la ecuación de Poisson generalizada.13 Para este caso introducimos las ideas básicas de
- la formulación débil o variacional (Sección 3.4.1),
- la aproximación de Galerkin (Sección 3.4.1.4), y
- la discretización por elementos finitos (Sección 3.4.1.5).
Luego en la Sección 3.4.2 aplicamos estas ideas para obtener las versiones completamente discretizadas de las ecuaciones de difusión multigrupo, que también son elípticas pero el problema deja de ser un escalar en cada nodo espacial y su operador no es simétrico para G>1. Finalmente en la Sección 3.4.3 hacemos lo mismo para transporte por S_N multigrupo. En este caso la incógnita también tiene varios grados de libertad en cada nodo espacial. Pero además el operador es parabólico de primer orden y la formulación numérica requiere de un término de estabilización.
3.4.1 Ecuación de Poisson generalizada
Comencemos resolviendo la ecuación escalar elíptica de Poisson generalizada (en el sentido de que el coeficiente del operador diferencial puede depender del espacio) sobre un dominio espacial D-dimensional U \in \mathbb{R}^D—cuya frontera es \partial U—con condiciones de contorno de Dirichlet homogéneas en \Gamma_D \in \partial U y condiciones arbitrarias de Neumann en \Gamma_N \in \partial U tal que \Gamma_D \cup \Gamma_N = \partial U y \Gamma_D \cap \Gamma_N = \emptyset (figura 3.6):

\begin{cases} -\text{div} \Big[ k(\mathbf{x}) \cdot \text{grad} \left[ u(\mathbf{x}) \right] \Big] = f(\mathbf{x}) & \forall\mathbf{x} \in U \\ u(\mathbf{x}) = 0 & \forall \mathbf{x} \in \Gamma_D \\ k(\mathbf{x}) \cdot \Big[ \text{grad} \left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big] = p(\mathbf{x}) & \forall \mathbf{x} \in \Gamma_N \end{cases} \tag{3.22} donde \hat{\mathbf{n}} es la normal externa a la frontera \partial U en el punto \mathbf{x}.
3.4.1.1 Formulaciones fuertes y débiles
Definición 3.12 (formulación fuerte) Llamamos a la ecuación diferencial propiamente dicha junto con sus condiciones de contorno, tal como las escribimos en la ecuación 3.22, la formulación fuerte del problema.
Observación. En la formulación fuerte, todas las funciones deben ser derivables al menos hasta el orden apropiado según dónde aparezca cada una. Por ejemplo, en la ecuación 3.22, tanto u como el producto k \nabla u deben ser derivables. Este requerimiento usualmente es demasiado restrictivo en aplicaciones físicas. Por ejemplo, la formulación fuerte del problema de conducción de calor no está bien definida en las interfaces entre materiales con diferentes conductividades k a cada lado de la interfaz.
Multipliquemos ambos miembros de la ecuación diferencial por una cierta función v(\mathbf{x}) que llamamos “de prueba”:14
-v(\mathbf{x}) \cdot \text{div} \Big[ k(\mathbf{x}) \cdot \text{grad} \left[ u(\mathbf{x}) \right] \Big] = v(\mathbf{x}) \cdot f(\mathbf{x}) \tag{3.23}
Esta función de prueba v(\mathbf{x}) puede ser (en principio) arbitraria, pero requerimos que se anule en \Gamma_D. Es decir, por ahora pedimos que u(\mathbf{x}) y v(\mathbf{x}) satisfagan las mismas condiciones de contorno de Dirichlet homogéneas (aunque no necesariamente las de Neumann).
Teorema 3.4 (de la divergencia) En un dominio conexo U \in \mathbb{R}^D, la integral de volumen sobre U de la divergencia de una función vectorial continua \mathbf{F}(\mathbf{x}) : U \mapsto \mathbb{R}^D es igual a la integral de superficie del producto interno entre \mathbf{F} y la normal externa \hat{\mathbf{n}} a la frontera \partial U:
\int_U \mathrm{div} \left[ \mathbf{F}(\mathbf{x}) \right] \, d^D\mathbf{x} = \int_{\partial U} \mathbf{F}(\mathbf{x}) \cdot \hat{\mathbf{n}} \, d^{D-1}\mathbf{x}
Prueba. Cualquier libro de Análisis II.
Corolario 3.5 (fórmula de Green) En un dominio conexo U \in \mathbb{R}^D, sean u(\mathbf{x}), v(\mathbf{x}) y k(\mathbf{x}) funciones continuas U \mapsto \mathbb{R}. Entonces
\begin{aligned} \int_U v(\mathbf{x}) \cdot \mathrm{div} \Big[ k(\mathbf{x}) \cdot \mathrm{grad} \left[ u(\mathbf{x}) \right] \Big] \,d^D\mathbf{x} =& -\int_U \mathrm{grad} \left[ v(\mathbf{x}) \right] \cdot k(\mathbf{x}) \cdot \mathrm{grad} \left[ u(\mathbf{x}) \right] \, d^D\mathbf{x} \\ & \quad\quad + \int_{\partial U} v(\mathbf{x}) \cdot \left[ k(\mathbf{x}) \cdot \Big( \mathrm{grad}\left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big) \right] \, d^{D-1}\mathbf{x} \end{aligned} siendo \hat{\mathbf{n}} la normal exterior a la frontera \partial U en el punto \mathbf{x}.
Prueba. Recordando el teorema 2.9 de la generalización de la derivada de un producto que dice que
\text{div} \big[ a \cdot \mathbf{b} \big ] = a \cdot \text{div} \left[\mathbf{b}\right] + \mathbf{b} \cdot \text{grad}\left[a\right] entonces para a = v y \mathbf{b} = k \nabla u
\text{div} \Big[ v(\mathbf{x}) \cdot k(\mathbf{x}) \cdot \text{grad}\left[ u(\mathbf{x})\right] \Big] = v(\mathbf{x}) \cdot \text{div}\Big[ k(\mathbf{x}) \cdot \text{grad}\left[ u(\mathbf{x})\right] \Big] + k(\mathbf{x}) \cdot \text{grad}\left[u(\mathbf{x})\right] \cdot \text{grad}\left[v(\mathbf{x})\right]
Integrando sobre el volumen U15
\begin{aligned} \int_U \text{div} \Big[ v(\mathbf{x}) \cdot k(\mathbf{x}) \cdot \text{grad}\left[ u(\mathbf{x})\right] \Big] \, d^D\mathbf{x} =& \int_U v(\mathbf{x}) \cdot \text{div}\Big[ k(\mathbf{x}) \cdot \text{grad}\left[ u(\mathbf{x})\right] \Big] \, d^D\mathbf{x} \\ &\quad + \int_U k(\mathbf{x}) \cdot \text{grad}\left[u(\mathbf{x})\right] \cdot \text{grad}\left[v(\mathbf{x})\right] \, d^D\mathbf{x} \end{aligned}
Haciendo \mathbf{F}(\mathbf{x}) = v(\mathbf{x}) \cdot k(\mathbf{x}) \cdot \text{grad}\left[ u(\mathbf{x})\right] en el teorema 3.4 tenemos
\int_U \text{div} \Big[ v(\mathbf{x}) \cdot k(\mathbf{x}) \cdot \text{grad}\left[ u(\mathbf{x})\right] \Big] \, d^D\mathbf{x} = \int_{\partial U} v(\mathbf{x}) \cdot \left[ k(\mathbf{x}) \cdot \Big( \text{grad}\left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big) \right] \, d^{D-1}\mathbf{x}
Igualando los miembros derechos de las últimas dos expresiones
\begin{aligned} \int_{\partial U} v(\mathbf{x}) \cdot \left[ k(\mathbf{x}) \cdot \Big( \text{grad}\left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big) \right] \, d^{D-1}\mathbf{x} =& \int_U v(\mathbf{x}) \cdot \text{div}\Big[ k(\mathbf{x}) \cdot \text{grad}\left[ u(\mathbf{x})\right] \Big] \, d^D\mathbf{x} \\ &\quad + \int_U k(\mathbf{x}) \cdot \text{grad}\left[u(\mathbf{x})\right] \cdot \text{grad}\left[v(\mathbf{x})\right] \, d^D\mathbf{x} \end{aligned}
Reordenando los términos, llegamos a la tesis del teorema.
Como \Gamma_D \cup \Gamma_N = \partial U y \Gamma_D \cap \Gamma_N = \emptyset, entonces podemos escribir la integral de superficie sobre la frontera \partial U como suma de dos integrales con el mismo integrando, una sobre \Gamma_D y otra sobre \Gamma_N:
\begin{aligned} \int_{\partial U} v(\mathbf{x}) \cdot \left[ k(\mathbf{x}) \cdot \Big( \mathrm{grad}\left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big) \right] \, d^{D-1}\mathbf{x} =& \int_{\Gamma_D} v(\mathbf{x}) \cdot \left[ k(\mathbf{x}) \cdot \Big( \mathrm{grad}\left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big) \right] \, d^{D-1}\mathbf{x} \\ &\quad + \int_{\Gamma_N} v(\mathbf{x}) \cdot \left[ k(\mathbf{x}) \cdot \Big( \mathrm{grad}\left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big) \right] \, d^{D-1}\mathbf{x} \end{aligned}
Pero
habíamos pedido que v(\mathbf{x}) se anule en \Gamma_D
v(\mathbf{x}) = 0 \quad \forall \mathbf{x} \in \Gamma_D
la condición de contorno de Neumann indica que
k(\mathbf{x}) \cdot \Big[ \text{grad} \left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big] = p(\mathbf{x}) \quad \forall \mathbf{x} \in \Gamma_N
por lo que
\int_{\partial U} v(\mathbf{x}) \cdot \left[ k(\mathbf{x}) \cdot \Big( \mathrm{grad}\left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big) \right] \, d^{D-1}\mathbf{x} = \int_{\Gamma_N} v(\mathbf{x}) \cdot p(\mathbf{x}) \,d^{D-1}\mathbf{x}
Volvamos a la ecuación 3.23 e integremos ambos miembros sobre el dominio U
-\int_U v(\mathbf{x}) \cdot \text{div} \Big[ k(\mathbf{x}) \cdot \text{grad} \left[ u(\mathbf{x}) \right] \Big] \,d^D\mathbf{x} = \int_U v(\mathbf{x}) \cdot f(\mathbf{x}) \,d^D\mathbf{x}
Ahora usemos la fórmula de Green y el hecho de que v(\mathbf{x}) se anula en \Gamma_D para obtener
\int_U \text{grad} \left[ v(\mathbf{x}) \right] \cdot k(\mathbf{x}) \cdot \text{grad} \left[ u(\mathbf{x}) \right] \,d^D\mathbf{x} = \int_U v(\mathbf{x}) \cdot f(\mathbf{x}) \,d^D\mathbf{x} + \int_{\Gamma_N} p(\mathbf{x}) \cdot v(\mathbf{x}) \,d^{D-1}\mathbf{x} \tag{3.24}
Definición 3.13 (formulación débil) Llamamos a la expresión que resulta de
- multiplicar ambos miembros de la ecuación diferencial por una función arbitraria llamada “de prueba” que se anula en \Gamma_D,
- integrar sobre el dominio espacial,
- aplicar fórmulas de cálculo vectorial, y
- reemplazar la condición de contorno de Neumann en las integrales de superficie
tal como la ecuación 3.24, junto con los requerimientos que deben satisfacer tanto la función incógnita como la función de prueba, la formulación débil o variacional del problema. Estrictamente hablando, la formulación débil de una ecuación diferencial es
\text{encontrar~} u(\mathbf{x}) \in V: \quad \mathcal{a} \Big(u(\mathbf{x}), v(\mathbf{x})\Big) = \mathcal{B} \Big(v(\mathbf{x})\Big) \quad \forall v(\mathbf{x}) \in V donde V es un espacio funcional apropiado, por ejemplo el H^1_0(U) de las funciones U \in \mathbb{R}^D \mapsto \mathbb{R} cuyo gradiente (el superíndice uno) es de cuadrado integrable en el dominio U y que se anulan en \Gamma_D (el subíndice cero)
V = H^1_0 (U) = \left\{ v \in H^1_0 (U) : \int_U \left( \nabla v \right)^{2} \,d^D\mathbf{x} < \infty \wedge v(\mathbf{x}) = 0 \forall \mathbf{x} \in \Gamma_D \right\} y los operadores \mathcal{a}(u,v) : V \times V \mapsto \mathbb{R} y \mathcal{B}(v) : V \mapsto \mathbb{R} se obtienen a partir de los cuatro pasos arriba mencionados. En particular, para el problema generalizado de Poisson de la formulación de la ecuación 3.24, es
\begin{aligned} \mathcal{a}(u,v) &= \int_U \text{grad}\Big[ v(\mathbf{x}) \Big] \cdot k(\mathbf{x}) \cdot \text{grad}\Big[ u(\mathbf{x}) \Big] \, d^D \mathbf{x} \\ \mathcal{B}(v) &= \int_U v(\mathbf{x}) \cdot f(\mathbf{x}) \, d^D \mathbf{x} + \int_{\Gamma_N} v(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1} \mathbf{x} \end{aligned} \tag{3.25}
Observación. En la formulación débil la derivabilidad es más laxa que en la formulación fuerte. De ahí su nombre: las funciones deben cumplir requerimientos más débiles. Por un lado, al involucrar una operación de integración sobre el dominio y aplicar fórmulas de Green, los requerimientos de derivabilidad disminuyen un grado: en la formulación fuerte 3.22, u tiene que ser derivable dos veces ya que el operador es esencialmente el laplaciano mientras que en la formulación débil 3.24 sólo involucra el gradiente. De hecho, ni siquiera hace falta que las funciones sean tan derivables según en el lugar dónde aparecen en la formulación ya que las las integrales deben tomarse según el sentido de Lebesgue y no según el sentido de como Riemann: todas las funciones dentro de las integrales pueden ser discontinuas en un sub-espacio de medida nula. En efecto, la formulación débil del problema de conducción de calor con conductividad discontinua en interfaces materiales está bien definida. Por un lado las interfaces materiales son un sub-espacio de medida nula y por otro la conductividad k(\mathbf{x}) no tiene aplicado ningún operador diferencial sino que es integrado (en el sentido de Lebesgue) sobre el dominio espacial U.
Observación. La formulación débil de la ecuación de conducción de calor derivada en la ecuación 3.24 incluye la posibilidad de que la conductividad k(\mathbf{x}) pueda depender del espacio e incluso ser discontinua en interfaces materiales. Más aún, la derivación propuesta puede ser extendida para el caso no lineal en el cual la conductividad pueda depender de la incógnita k(u). Ver por ejemplo el problema de conducción de calor no lineal del Sección B.3.1.3.
Observación. El nombre variacional viene del hecho de requerir que \mathcal{a}(u,v) = \mathcal{B}(v) para todas las posibles funciones de prueba v(\mathbf{x}) \in V. Es decir, de requerir que v pueda “variar” arbitrariamente (siempre que se anule en \Gamma_D) y la igualdad se siga manteniendo.
Observación. La formulación fuerte incluye las condiciones de contorno en su enunciado. Las condiciones de Neumann aparecen naturalmente en los términos de superficie luego de aplicar las fórmulas de Green y las condiciones de Dirichlet están esencialmente en el espacio vectorial V donde se busca la solución u. Las primeras se llaman naturales y las segundas esenciales.
Teorema 3.5 El problema débil es equivalente al fuerte en el sentido de distribuciones, es decir, ambas formulaciones coinciden excepto en a lo más un sub-conjunto de U de medida cero.
Definición 3.14 (funcional lineal) Un funcional \mathcal{B}(v) : V \mapsto \mathbb{R} es lineal si
\mathcal{B}(\alpha \cdot v_1 + \beta \cdot v_2) = \alpha \cdot \mathcal{B}(v_1) + \beta \cdot \mathcal{B}(v_2)
Definición 3.15 (operador bi-lineal) Un operador \mathcal{a}(v,u) : V \times V \mapsto \mathbb{R} es bi-lineal si
\mathcal{a}(\alpha \cdot v_1 + \beta \cdot v_2, u) = \alpha \cdot \mathcal{a}(v_1,u) + \beta \cdot \mathcal{a}(v_2,u) y \mathcal{a}(v, \alpha \cdot u_1 + \beta \cdot u_2) = \alpha \cdot \mathcal{a}(v,u_1) + \beta \cdot \mathcal{a}(v,u_2)
Definición 3.16 (operador simétrico) Un operador \mathcal{a}(v,u) es simétrico si
\mathcal{a}(v,u) = \mathcal{a}(u,v)
Definición 3.17 (operador coercitivo) Un operador \mathcal{a}(v,u) : V \times V \mapsto \mathbb{R} es coercitivo si existe una constante \alpha >0 tal que
\mathcal{a}(v,v) \geq \alpha \cdot || v ||^2_V
Corolario 3.6 Si \mathcal{a}(v,u) es coercitivo entonces
||v||_{\mathcal{a}} = \sqrt{\mathcal{a}(v,v)} es una norma.
Teorema 3.6 El operador
\mathcal{a}(u,v) = \int_U \mathrm{grad}\Big[ v(\mathbf{x}) \Big] \cdot k(\mathbf{x}) \cdot \mathrm{grad}\Big[ u(\mathbf{x}) \Big] \, d^D \mathbf{x} es coercitivo si k(\mathbf{x}) > 0 \forall \mathbf{x} \in U.
Prueba. La demostración detallada se puede encontrar la sección 5.3 de [3] e en involucra análisis funcional y algunas desigualdades, como la de Poincaré. La idea básica es que \int_U [\nabla v]^2 d^D\mathbf{x} se comporta en forma similar a \int_U v^2 d^D\mathbf{x}.
Teorema 3.7 (de Lax-Milgram) Dada una formulación débil
\text{encontrar~} u \in V: \quad \mathcal{a} (u, v) = \mathcal{B} (v) \quad \forall v \in V siendo
- V un sub-espacio de H^1(U),
- \mathcal{a} : V \times V \mapsto \mathbb{R} un operador continuo, bi-lineal y coercitivo, y
- \mathcal{B} : V \mapsto \mathbb{R} un funcional continuo y lineal
entonces la solución u existe y es única.
3.4.1.2 Condiciones de contorno de Dirichlet no homogéneas
Hasta ahora las condiciones de contorno de Dirichlet han sido iguales a cero, ya que al pedir que tanto la incógnita u como las funciones de prueba v pertenezcan a H^1_0 podemos
- satisfacer las condiciones esenciales sobre u, y
- anular el término de superficie sobre \Gamma_D de la fórmula de Green
Si el problema a resolver tiene una condición de contorno no homogénea, digamos
\begin{cases} -\text{div} \Big[ k(\mathbf{x}) \cdot \text{grad} \left[ u(\mathbf{x}) \right] \Big] = f(\mathbf{x}) & \forall\mathbf{x} \in U \\ u(\mathbf{x}) = g(\mathbf{x}) & \forall \mathbf{x} \in \Gamma_D \\ k(\mathbf{x}) \cdot \Big[ \text{grad} \left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big] = p(\mathbf{x}) & \forall \mathbf{x} \in \Gamma_N \end{cases} \tag{3.26} entonces una idea sería pedir que v \in H^1_0 pero que u \in H^1_g tal que
H^1_g (U) = \left\{ v \in H^1_g (U) : \int_U \left( \nabla v \right)^{2} \,d^D\mathbf{x} < \infty \wedge v(\mathbf{x}) = g(\mathbf{x})~\forall \mathbf{x} \in \Gamma_D \right\}
Este planteo, además de ser poco elegante al romper la simetría entre u y v, tiene un problema insalvable: H^1_g es un conjunto16 pero no un espacio ya que la suma de dos funciones u_1 \in H^1_g y u_2 \in H^1_g no están en H^1_g sino en H^1_{2g}. Esto hace que no podamos escribir fácilmente a la incógnita u como una combinación lineal de una base, que es lo primero que hacemos en la Sección 3.4.1.4 que sigue.
Una alternativa es considerar una función continua u_g \in H^1_g y escribir
u_h(\mathbf{x}) = u(\mathbf{x}) - u_g(\mathbf{x}) \tag{3.27} donde u_h \in H^1_0, es decir, se anula en \Gamma_D (el subíndice h quiere decir “homogénea”). Si el operador \mathcal{a} es bi-lineal, entonces podemos escribir el problema
\text{encontrar~} u \in V: \quad \mathcal{a} \left(u, v\right) = \mathcal{B} \left(v\right) \quad \forall v \in V como
\text{encontrar~} u_h \in V: \quad \mathcal{a} \left(u_h, v\right) = \mathcal{B} \left(v\right) - \mathcal{a} \left(u_g, v\right) \quad \forall v \in V donde ahora tanto la incógnita parcial u_h como las funciones de prueba v pertenecen a V = H^1_0 y todos los datos del problema están en el miembro derecho de la igualdad. Podemos obtener la incógnita original u a partir de la ecuación 3.27 como
u(\mathbf{x}) = u_h(\mathbf{x}) + u_g(\mathbf{x})
Observación.
Si bien este procedimiento es matemáticamente correcto, no parece sencillo encontrar una función u_g \in H^1_g apropiada para una condición de contorno arbitraria g(\mathbf{x}). En la Sección 3.4.1.5 mostramos que en un espacio vectorial de dimensión finita el procedimiento es más sencillo. En el capítulo 4 que sigue mostramos que la implementación práctica de este tipo de condiciones de contorno es más sencilla todavía.
3.4.1.3 Condiciones de contorno de Robin
Si el problema tiene una condición de contorno de Robin, digamos
\gamma(\mathbf{x}) \cdot u(\mathbf{x}) + k(\mathbf{x}) \cdot \Big[ \text{grad} \left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big] = \beta(\mathbf{x}) \quad \forall \mathbf{x} \in \Gamma_R podemos pasar el primer término al otro miembro y llamar p(\mathbf{x}) a la expresión resultante
k(\mathbf{x}) \cdot \Big[ \text{grad} \left[ u(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big] = \beta(\mathbf{x}) - \gamma(\mathbf{x}) \cdot u(\mathbf{x}) = p(\mathbf{x})
De esta manera, una condición de Robin tendrá una contribución sobre el operador \mathcal{a}(u,v)
\int_{\Gamma_R} v(\mathbf{x}) \cdot \gamma(\mathbf{x}) \cdot u(\mathbf{x}) \, d^{D-1}\mathbf{x} y otra contribución sobre el funcional \mathcal{B}(v)
\int_{\Gamma_R} u(\mathbf{x}) \cdot \beta(\mathbf{x}) \, d^{D-1}\mathbf{x}
Observación. Si \gamma(\mathbf{x}) es lo suficientemente negativo, el operador \mathcal{a}(u,v) puede perder su coercitividad.
3.4.1.4 Aproximación de Galerkin
Usando las ideas desarrolladas en la sección anterior, podemos definir una discretización espacial muy fácilmente como sigue.
Definición 3.18 (problema de Galerkin) Sea V_N un sub-espacio de V = H^1_0(U) de dimensión finita N. Llamamos problema de Galerkin a
\text{encontrar~} u_N \in V_N: \quad \mathcal{a} (u_N, v_N) = \mathcal{B} (v_N) \quad \forall v_N \in V_N
Como V_N es un espacio vectorial de dimensión N entonces podemos encontrar N funciones h_i(\mathbf{x}) que formen una base de V_N
V_N = \text{span}\Big\{ h_1(\mathbf{x}), h_2(\mathbf{x}), \dots, h_N(\mathbf{x})\Big\}
En efecto, v_N \in V_N puede ser escrita como una combinación lineal de las N funciones h_i(\mathbf{x})
v_N(\mathbf{x}) = \sum_{i=1}^N v_i \cdot h_i(\mathbf{x}) \tag{3.28}
Para \mathcal{a} bi-lineal y \mathcal{B} lineal,
\begin{aligned} 0 &= \mathcal{a} \Big(u_N(\mathbf{x}), v_N(\mathbf{x})\Big) - \mathcal{B} \Big(v_N(\mathbf{x})\Big)\\ 0 &= \mathcal{a} \left(u_N(\mathbf{x}), \sum_{i=1}^N v_i \cdot h_i\left(\mathbf{x}\right)\right) - \mathcal{B} \left(\sum_{i=1}^N v_i \cdot h_i\left(\mathbf{x}\right)\right) \\ 0 &= \sum_{i=1}^N v_i \cdot \left[ \mathcal{a} \Big(u_N(\mathbf{x}), h_i\left(\mathbf{x}\right)\Big) - \mathcal{B} \Big(h_i\left(\mathbf{x}\right)\Big) \right] \\ \end{aligned}
Como esta igualdad tiene que cumplirse \forall v_N \in V_N entonces cada corchete debe anularse independientemente de v_i, lo que implica que
\mathcal{a} \Big(u_N(\mathbf{x}), h_i\left(\mathbf{x}\right)\Big) = \mathcal{B} \Big(h_i\left(\mathbf{x}\right)\Big) \quad \text{para $i=1,\dots,N$}
De la misma manera, u_N \in V_N por lo que u_N(\mathbf{x}) = \sum_{j=1}^N u_j \cdot h_j(\mathbf{x}) entonces
\begin{aligned} \mathcal{a} \Big(\sum_{j=1}^N u_j \cdot h_j(\mathbf{x}), h_i\left(\mathbf{x}\right)\Big) &= \mathcal{B} \Big(h_i\left(\mathbf{x}\right)\Big) \\ \sum_{j=1}^N \mathcal{a} \Big(h_i(\mathbf{x}), h_j\left(\mathbf{x}\right)\Big) \cdot u_j &= \mathcal{B} \Big(h_i\left(\mathbf{x}\right)\Big) \quad \text{para $i=1,\dots,N$} \end{aligned} que podemos escribir en forma matricial como
\mathsf{A} \cdot \mathbf{u} = \mathbf{b} \tag{3.29} siendo
\mathsf{A} = \begin{bmatrix} \mathcal{a}(h_1,h_1) & \mathcal{a}(h_1,h_2) & \cdots & \mathcal{a}(h_1,h_j) & \cdots & \mathcal{a}(h_1,h_N) \\ \mathcal{a}(h_2,h_1) & \mathcal{a}(h_2,h_2) & \cdots & \mathcal{a}(h_2,h_j) & \cdots & \mathcal{a}(h_2,h_N) \\ \vdots & \vdots & \ddots & \vdots & \ddots & \vdots \\ \mathcal{a}(h_i,h_1) & \mathcal{a}(h_i,h_2) & \cdots & \mathcal{a}(h_i,h_j) & \cdots & \mathcal{a}(h_i,h_N) \\ \vdots & \vdots & \ddots & \vdots & \ddots & \vdots \\ \mathcal{a}(h_N,h_1) & \mathcal{a}(h_N,h_2) & \cdots & \mathcal{a}(h_N,h_j) & \cdots & \mathcal{a}(h_N,h_N) \\ \end{bmatrix}
\mathbf{u} = \begin{bmatrix} u_1 \\ u_2 \\ \vdots \\ u_i \\ \vdots \\ u_N \\ \end{bmatrix} \quad\quad\quad\quad \mathbf{b} = \begin{bmatrix} \mathcal{B}(h_1) \\ \mathcal{B}(h_2) \\ \vdots \\ \mathcal{B}(h_i) \\ \vdots \\ \mathcal{B}(h_N) \\ \end{bmatrix}
Corolario 3.7 Si el operador \mathcal{a} es simétrico entonces la matriz \mathsf{A} también es simétrica.
Teorema 3.8 Si el operador \mathcal{a} es bi-lineal y coercitivo entonces la matriz \mathsf{A} es definida positiva.
Prueba. \begin{aligned} \mathbf{v}^T \cdot \mathsf{A} \cdot \mathbf{v} &= \sum_{i=1}^N \sum_{j=1}^N v_i \cdot \mathcal{a}(h_i, h_j) \cdot v_j \\ &= \sum_{i=1}^N \sum_{j=1}^N \mathcal{a}(v_i \cdot h_i, v_j \cdot h_j) \\ &= \mathcal{a} \left( \sum_{i=1}^N v_i \cdot h_i, \sum_{j=1}^N v_j \cdot h_j\right) \\ &= \mathcal{a}(v_N, v_N) \geq \alpha\cdot ||v_N||_V^2 \geq 0 \end{aligned} para \alpha > 0. Dado que ||v_N||_V es una norma, la igualdad se cumple si y sólo si ||v_N||_V = 0, lo que implica que todos los elementos de v son nulos.
Observación. Ver [7] para una demostración alternativa.
Teorema 3.9 (existencia y unicidad) Si el operador \mathcal{a} es bi-lineal y coercitivo entonces el problema de Galerkin de la definición 3.18 existe y es único.
Prueba. Por el teorema 3.8 la matriz \mathsf{A} es definida positiva. Luego es invertible y la ecuación 3.29 \mathsf{A} \cdot \mathbf{u} = \mathbf{b} tiene solución única.
Teorema 3.10 (estabilidad) El método de Galerkin es estable con respecto a N.
Prueba. Sección 4.2.2 de [11].
Teorema 3.11 (consistencia) El método de Galerkin es fuertemente consistente, es decir
\mathcal{a}(u - u_N, v_N) = 0 \quad \forall v_N \in V_N
Prueba. Como u_N es una solución del problema de Galerkin entonces
\mathcal{a}(u_N, v_N) = \mathcal{B}(v_N) \quad \forall v_N \in V_N
Dado que V_N \subset V entonces la solución continua u \in V también satisface
\mathcal{a}(u, v_N) = \mathcal{B}(v_N) \quad \forall v_N \in V_N
Restando miembro a miembro
\mathcal{a}(u_N, v_N) - \mathcal{a}(u, v_N) = 0 de donde se sigue la tesis por la bi-linealidad.
Observación. El error u - u_N cometido por la aproximación de Galerkin es ortogonal al sub-espacio V_N en la norma
||v||_{\mathcal{a}} = \sqrt{\mathcal{a}(v,v)} Es decir, la solución aproximada u_N es
- La proyección ortogonal de la solución exacta u en el sub-espacio V_N.
- La solución que minimiza la distancia ||u -u_N||_{\mathcal{a}}.
Corolario 3.8 (convergencia) Si V_N \rightarrow V para N \rightarrow \infty entonces el método de Galerkin converge a la solución real u.
Observación. En esta Sección 3.4.1 se ha comenzado con la formulación fuerte de la ecuación diferencial (ecuación 3.22) y se ha llegado a un sistema lineal de ecuaciones algebraica (ecuación 3.29), pasando por la formulación débil (definición 3.13) y por la aproximación de Galerkin (definición 3.18):
\text{formulación fuerte} \quad \equiv \quad \text{formulación débil} \quad \approxident \quad \text{aproximación de Galerkin} \equiv \quad \mathsf{A} \cdot \mathbf{u} = \mathbf{b}
La primera equivalencia está probada por el teorema 3.5. No hay ninguna aproximación involucrada. Solamente hay que marcar que la equivalencia se mantiene en todo el dominio U excepto en, a lo más, un sub-conjunto de medida cero. La aproximación entre la formulación débil y el problema de Galerkin es la idea central del método numérico: pasar de una espacio vectorial V de dimensión infinita a un espacio vectorial V_N de dimensión finita. La equivalencia entre Galerkin y un sistema lineal de ecuaciones algebraicas (que puede ser resuelto con una computadora digital) funciona siempre y cuando el operador a(u,v) sea coercitivo y bi-lineal. Para problemas no lineales (por ejemplo para el caso en el que k dependiera de u) la última equivalencia se reemplaza por una formulación vectorial no lineal \mathbf{F}(\mathbf{u})=0. En la Sección 3.5.1 mencionamos brevemente cómo formular y resolver este tipo de problemas.
3.4.1.5 Elementos finitos
Tomemos un dominio U\in \mathbb{R}^D y consideremos J puntos \mathbf{x}_j \in U. Estos puntos \mathbf{x}_j para j=1,\dots,J incluyen la frontera \Gamma_N con condiciones de contorno de Neumann pero no incluyen a \Gamma_D con condiciones de Dirichlet. Por ejemplo, en la figura 3.7 tenemos J=32. Supongamos que existen J funciones h_j(\mathbf{x}) “de forma”17 que cumplen simultáneamente
\begin{cases} h_j(\mathbf{x}_i) = \delta_{ji} \\ h_j(\mathbf{x}) = 0 \quad \forall \mathbf{x} \in \Gamma_D \end{cases} \tag{3.30}

Sea V_J el espacio vectorial de dimensión J generado por estas J funciones de forma h_j(\mathbf{x}). Como ya hicimos en la ecuación 3.28, escribimos a una cierta función v(\mathbf{x}) \in V_J como una combinación lineal de los elementos de la base
v(\mathbf{x}) = \sum_{j=1}^J v_j \cdot h_j(\mathbf{x}) \tag{3.31}
Podemos escribir esta expansión en forma matricial como
v(\mathbf{x}) = \mathsf{H}(\mathbf{x}) \cdot \mathbf{v} = \mathbf{v}^T \cdot \mathsf{H}^T(\mathbf{x}) con18
\mathsf{H}(\mathbf{x}) = \begin{bmatrix} h_1(\mathbf{x}) & h_2(\mathbf{x}) & \cdots & h_j(\mathbf{x}) & \cdots & h_J(\mathbf{x}) \end{bmatrix} \tag{3.32} y \mathbf{v} = \begin{bmatrix} v(\mathbf{x}_1) \\ v(\mathbf{x}_2) \\ \vdots \\ (\mathbf{x}_j) \\ \vdots \\ (\mathbf{x}_J) \\ \end{bmatrix}
De la misma forma, el gradiente \nabla v es
\text{grad} \Big[ v(\mathbf{x}) \Big] = \begin{bmatrix} \displaystyle\frac{\partial v}{\partial x} \\ \displaystyle\frac{\partial v}{\partial y} \\ \displaystyle\frac{\partial v}{\partial z} \end{bmatrix} = \begin{bmatrix} \displaystyle \sum_{j=1}^J v^{(j)} \cdot \frac{\partial h_j}{\partial x} \\ \displaystyle \sum_{j=1}^J v^{(j)} \cdot \frac{\partial h_j}{\partial y} \\ \displaystyle \sum_{j=1}^J v^{(j)} \cdot \frac{\partial h_j}{\partial z} \end{bmatrix} = \mathsf{B}(\mathbf{x}) \cdot \mathbf{v} con
\mathsf{B}(\mathbf{x}) = \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial x} & \displaystyle \frac{\partial h_2}{\partial x} & \cdots & \displaystyle \frac{\partial h_j}{\partial x} & \cdots & \displaystyle \frac{\partial h_J}{\partial x} \\ \displaystyle \frac{\partial h_1}{\partial y} & \displaystyle \frac{\partial h_2}{\partial y} & \cdots & \displaystyle \frac{\partial h_j}{\partial y} & \cdots & \displaystyle \frac{\partial h_J}{\partial y} \\ \displaystyle \frac{\partial h_1}{\partial z} & \displaystyle \frac{\partial h_2}{\partial z} & \cdots & \displaystyle \frac{\partial h_j}{\partial z} & \cdots & \displaystyle \frac{\partial h_J}{\partial z} \\ \end{bmatrix} \tag{3.33}
Reemplazando la forma particular del operador \mathcal{a} y del funcional \mathcal{B} para el problema generalizado de Poisson de la ecuación 3.25, tenemos
\begin{aligned} \mathcal{a}(u,v) &= \int_U \text{grad}\Big[ v(\mathbf{x}) \Big] \cdot k(\mathbf{x}) \cdot \text{grad}\Big[ u(\mathbf{x}) \Big] \, d^D \mathbf{x} \\ &= \int_U \mathbf{v}^T \cdot \mathsf{B}^T(\mathbf{x}) \cdot k(\mathbf{x}) \cdot \mathsf{B}(\mathbf{x}) \cdot \mathbf{u} \,\, d^D\mathbf{x} \\ &= \mathbf{v}^T \cdot \left[ \int_U \mathsf{B}^T(\mathbf{x}) \cdot k(\mathbf{x}) \cdot \mathsf{B}(\mathbf{x}) \, d^D\mathbf{x} \right] \cdot \mathbf{u} \\ \end{aligned}
\begin{aligned} \mathcal{B}(v) &= \int_U v(\mathbf{x}) \cdot f(\mathbf{x}) \, d^D \mathbf{x} + \int_{\Gamma_N} v(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1} \mathbf{x} \\ &= \int_U \mathbf{v}^T \cdot \mathsf{H}^T(\mathbf{x}) \cdot f(\mathbf{x}) \, d^D \mathbf{x} + \int_{\Gamma_N} \mathbf{v}^T \cdot \mathsf{H}^T(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1} \mathbf{x} \\ &= \mathbf{v}^T \cdot \left[ \int_{U} \mathsf{H}^T(\mathbf{x}) \cdot f(\mathbf{x}) \, d^D \mathbf{x} + \int_{\Gamma_N} \mathsf{H}^T(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1}\mathbf{x} \right] \end{aligned}
Como \mathcal{a}(u,v) = \mathcal{B}(v) \quad \forall v \in V_J entonces llegamos otra vez a
\mathsf{A} \cdot \mathbf{u} = \mathbf{b} donde ahora tenemos una representación explícita particular para \mathsf{A} \in \mathbb{R}^{J \times J} y \mathbf{u} \in \mathbb{R}^J a partir de las ecuaciones [-ecuación 3.32} y 3.33 como
\begin{aligned} \mathsf{A} &= \int_U \mathsf{B}^T(\mathbf{x}) \cdot k(\mathbf{x}) \cdot \mathsf{B}(\mathbf{x}) \, d^D\mathbf{x} \\ \mathbf{b} &= \int_{\Gamma_N} \mathsf{H}^T(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1} \mathbf{x} + \int_{\Gamma_N} \mathsf{H}^T(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1}\mathbf{x} \end{aligned} \tag{3.34}
Una vez más, tal como hemos dicho en la observación sobre la construcción de la función u_g necesaria para satisfacer condiciones de contorno de Dirichlet no homogéneas , estas últimas dos expresiones son correctas. Pero no parece sencillo…
- encontrar las J funciones de forma h_j(\mathbf{x}) adecuadas que cumplan las condiciones 3.30 (como por ejemplo las ilustradas en la figura 3.8), ni
- calcular las integrales para obtener la matriz \mathsf{A} \in \mathbb{R}^{J \times J} y el vector \mathbf{b} \in \mathbb{R}^J.


Justamente, el método de elementos finitos propone una forma sistemática para atacar estos dos puntos a partir de explotar la topología de los J puntos \mathbf{x}_j de la figura 3.7. El hecho de no haber incluido puntos sobre la frontera \Gamma_D en el conjunto de J funciones de forma de alguna manera rompe el sistematismo necesario para aplicar el método. Lo primero que tenemos que hacer entonces es incluir puntos sobre la frontera \Gamma_D. Digamos que hay J_D puntos sobre \Gamma_D. Entonces agregamos J_D funciones de forma para j=J+1,\dots,J+J_D a las cuales les pedimos que
h_j(\mathbf{x}_i) = \delta_{ji} \quad \text{para \quad $j=J+1,\dots,J+J_D$ \quad e \quad $i=1,\dots,J+J_D$}\\
Es decir, que estas nuevas funciones de forma se anulen en los demás J+J_D-1 puntos pero no necesitamos que se anulen en la frontera como le pedíamos a las primeras funciones de forma “originales” para j \leq J. Como las funciones de forma originales cumplen las condiciones de la ecuación 3.30, es decir sí se anulan en
- todos los nodos diferentes de j, y
- en todos los puntos \mathbf{x} \in \Gamma_D
entonces también cumplen
h_j(\mathbf{x}_i) = \delta_{ji} \quad \text{para \quad $j=1,\dots,J$ \quad e \quad $i=1,\dots,J+J_D$}\\
Luego
h_j(\mathbf{x}_i) = \delta_{ji} \quad \text{para \quad $j=1,\dots,J+J_D$ \quad e \quad $i=1,\dots,J+J_D$}\\ y recuperamos una parte la sistematicidad requerida para aplicar el método de elementos finitos. Para recuperar la otra parte re-escribimos la ecuación 3.31 poniendo coeficientes iguales a cero en las funciones de forma sobre \Gamma_D
v(\mathbf{x}) = \sum_{j=1}^J v^{(j)} \cdot h_j(\mathbf{x}) = \sum_{j=1}^J v^{(j)} \cdot h_j(\mathbf{x}) + \sum_{j=J+1}^{J+J_D} 0 \cdot h_j(\mathbf{x}) que, en forma matricial, queda
v(\mathbf{x}) = \tilde{\mathsf{H}}(\mathbf{x}) \cdot \tilde{\mathbf{v}} = \tilde{\mathbf{v}}^T \cdot \tilde{\mathsf{H}}^T(\mathbf{x}) donde ahora los objetos tildados son objetos “extendidos” incluyendo los J_D puntos sobre \Gamma_D como
\tilde{\mathsf{H}}(\mathbf{x}) = \begin{bmatrix} h_1(\mathbf{x}) & h_2(\mathbf{x}) & \cdots & h_j(\mathbf{x}) & \cdots & h_J(\mathbf{x}) & h_{J+1}(\mathbf{x}) & \cdots & h_{J+J_D}(\mathbf{x}) \end{bmatrix} \tag{3.35} y \tilde{\mathbf{v}} = \begin{bmatrix} v^{(1)} \\ v^{(2)} \\ \vdots \\ v^{(j)} \\ \vdots \\ v^{(J)} \\ 0 \\ \vdots \\ 0 \end{bmatrix}
De la misma manera extendemos la matriz \mathsf{B}(\mathbf{x}) como
\tilde{\mathsf{B}}(\mathbf{x}) = \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial x} & \displaystyle \frac{\partial h_2}{\partial x} & \cdots & \displaystyle \frac{\partial h_j}{\partial x} & \cdots & \displaystyle \frac{\partial h_J}{\partial x} & \displaystyle \frac{\partial h_{J+1}}{\partial x} & \cdots & \displaystyle \frac{\partial h_{J+J_D}}{\partial x} \\ \displaystyle \frac{\partial h_1}{\partial y} & \displaystyle \frac{\partial h_2}{\partial y} & \cdots & \displaystyle \frac{\partial h_j}{\partial y} & \cdots & \displaystyle \frac{\partial h_J}{\partial y} & \displaystyle \frac{\partial h_{J+1}}{\partial y} & \cdots & \displaystyle \frac{\partial h_{J+J_D}}{\partial y} \\ \displaystyle \frac{\partial h_1}{\partial z} & \displaystyle \frac{\partial h_2}{\partial z} & \cdots & \displaystyle \frac{\partial h_j}{\partial z} & \cdots & \displaystyle \frac{\partial h_J}{\partial z} & \displaystyle \frac{\partial h_{J+1}}{\partial z} & \cdots & \displaystyle \frac{\partial h_{J+J_D}}{\partial z} \\ \end{bmatrix} \tag{3.36}
Repitiendo todos los pasos, el método de Galerkin requiere que
\tilde{\mathbf{v}}^T \cdot \left[ \int_U \tilde{\mathsf{B}}^T(\mathbf{x}) \cdot k(\mathbf{x}) \cdot \tilde{\mathsf{B}}(\mathbf{x}) \, d^D\mathbf{x} \right] \cdot \tilde{\mathbf{u}} = \tilde{\mathbf{v}}^T \cdot \left[ \int_{U} \tilde{\mathsf{H}}^T(\mathbf{x}) \cdot f(\mathbf{x}) \, d^D \mathbf{x} + \int_{\Gamma_N} \tilde{\mathsf{H}}^T(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1}\mathbf{x} \right] \tag{3.37} para todo \tilde{v}^T = \begin{bmatrix} v^{(j)} & \cdots \ v^{(J)} & 0 & \cdots & 0\end{bmatrix}.
Teorema 3.12 Este requerimiento es equivalente a \mathsf{A} \cdot \mathbf{u} = \mathbf{b}.
Prueba. Sean los objetos extendidos
\tilde{\mathbf{v}} = \begin{bmatrix} \mathbf{v} \\ \mathbf{0} \end{bmatrix} \quad \tilde{\mathsf{A}} = \begin{bmatrix} \mathsf{A} & \mathsf{C} \\ \mathsf{D} & \mathsf{E} \\ \end{bmatrix} \quad \tilde{\mathbf{u}} = \begin{bmatrix} \mathbf{u} \\ \mathbf{0} \end{bmatrix} \quad \tilde{\mathbf{b}} = \begin{bmatrix} \mathbf{b} \\ \mathbf{e} \end{bmatrix}
Entonces
\begin{aligned} \tilde{\mathbf{v}}^T \cdot \tilde{\mathsf{A}} \cdot \tilde{\mathbf{u}} &= \tilde{\mathbf{v}}^T \cdot \tilde{\mathbf{b}} \\ \begin{bmatrix} \mathbf{v}^T & \mathbf{0}^T \end{bmatrix} \cdot \begin{bmatrix} \mathsf{A} & \mathsf{C} \\ \mathsf{D} & \mathsf{E} \\ \end{bmatrix} \cdot \begin{bmatrix} \mathbf{u} \\ \mathbf{0} \end{bmatrix} & = \begin{bmatrix} \mathbf{v}^T & \mathbf{0}^T \end{bmatrix} \begin{bmatrix} \mathbf{b} \\ \mathbf{e} \end{bmatrix} \\ \begin{bmatrix} \mathbf{v}^T & \mathbf{0}^T \end{bmatrix} \cdot \begin{bmatrix} \mathsf{A} \cdot \mathbf{u} + \mathsf{C} \cdot \mathbf{0} \\ \mathsf{D} \cdot \mathbf{u} + \mathsf{E} \cdot \mathbf{0} \\ \end{bmatrix} &= \begin{bmatrix} \mathbf{v}^T & \mathbf{0}^T \end{bmatrix} \begin{bmatrix} \mathbf{b} \\ \mathbf{e} \end{bmatrix} \\ \mathbf{v}^T \cdot \mathsf{A} \cdot \mathbf{u} + \mathbf{0}^T \cdot \mathsf{D} \cdot \mathbf{u} &= \mathbf{v}^T \cdot \mathbf{b} + \mathbf{0}^T \cdot \mathbf{e}\\ \mathbf{v}^T \cdot \mathsf{A} \cdot \mathbf{u} &= \mathbf{v}^T \cdot \mathbf{b}\\ \end{aligned}
Como esta igualdad debe valer \forall \mathbf{v}, entonces \mathsf{A} \cdot \mathbf{u} - \mathbf{b} = 0.
Corolario 3.9 Si \tilde{\mathbf{v}}=\begin{bmatrix} \mathbf{v} & \mathbf{0}\end{bmatrix}^T y \tilde{\mathbf{u}}=\begin{bmatrix} \mathbf{u} & \mathbf{0}\end{bmatrix}^T entonces el contenido de las matrices \mathsf{C}, \mathsf{D} y \mathsf{E} y del vector \mathbf{e} es irrelevante.
Teorema 3.13 La matriz \tilde{\mathsf{A}} es singular. Más aún, \ker{(\tilde{\mathsf{A}})} = 1.
Corolario 3.10 Sean los objetos
\mathsf{K} = \begin{bmatrix} \mathsf{A} & \mathsf{C} \\ \mathsf{0} & \mathsf{I} \\ \end{bmatrix} \quad \mathbf{f} = \begin{bmatrix} \mathbf{b} \\ \mathbf{0} \\ \end{bmatrix} \tag{3.38} tales que \mathsf{A} \cdot \mathbf{u} = \mathbf{b}, donde \mathsf{I} es la matriz identidad de tamaño J_D \times J_D. Entonces el vector \mathbf{\varphi} tal que \mathsf{K} \cdot \mathbf{\varphi} = \mathbf{f} es igual a
\mathbf{\varphi} = \begin{bmatrix} \mathbf{u} \\ \mathbf{0} \\ \end{bmatrix}
Prueba. Sea \mathbf{\varphi} = \begin{bmatrix} \mathbf{\varphi}_1 & \mathbf{\varphi}_2 \end{bmatrix}^T. Entonces \mathsf{K} \cdot \mathbf{\varphi} es
\begin{bmatrix} \mathsf{A} & \mathsf{C} \\ \mathsf{0} & \mathsf{I} \end{bmatrix} \cdot \begin{bmatrix} \mathbf{\varphi}_1 \\ \mathbf{\varphi}_2 \end{bmatrix} = \begin{bmatrix} \mathsf{A} \cdot \mathbf{\varphi}_1 + \mathsf{C} \cdot \mathbf{\varphi}_2\\ \mathsf{0} \cdot \mathbf{\varphi}_1 + \mathsf{I} \cdot \mathbf{\varphi}_2 \end{bmatrix} = \begin{bmatrix} \mathbf{b}\\ \mathbf{0} \end{bmatrix}
De la segunda fila se tiene \mathbf{\varphi}_2 = \mathbf{0}. Reemplazando este resultado en la primera fila, \mathsf{A} \cdot \mathbf{\varphi}_1 = \mathbf{b}. Luego \mathbf{\varphi}_1 = \mathsf{A}^{-1} \cdot \mathbf{b} = \mathbf{u}.
La importancia de este resultado radica en que si pudiésemos construir la matriz extendida \tilde{\mathsf{A}} \in \mathbb{R}^{(J+J_D)\times(J+J_D)} donde el elemento de la fila i y la columna j es
\tilde{a}_{ij} = \mathcal{a}\Big(h_i(\mathbf{x}), h_j(\mathbf{x})\Big) \quad \text{para $i=1,\dots,J+J_D$ y $j=1,\dots,J+J_D$} sin distinguir entre nodos en U, en \Gamma_N o en \Gamma_D, entonces podríamos obtener la matriz \mathsf{K} reemplazando las filas correspondientes a i=J+1,\dots,J+J_D por todos ceros, excepto un uno (o cualquier valor \alpha \neq 0) en la diagonal. Al mismo tiempo, tendríamos que reemplazar los elementos del vector \mathbf{f}
f_j = \mathcal{B}\Big(h_j(\mathbf{x})\Big) \quad \text{para $J=1,\dots,J+J_D$} para j > J por f_j=0.
Definición 3.19 (matriz de rigidez) La matriz cuadrada \mathsf{K} de tamaño igual a la cantidad total J+J_D de nodos tal que \mathsf{K} \cdot \mathbf{\varphi} = \mathbf{f} se llama (usualmente) matriz de rigidez.
Teorema 3.14 La matriz de rigidez tiene inversa.
Prueba. La matriz \mathsf{K} tiene una estructura de bloque triangular superior
\mathsf{K} = \begin{bmatrix} \mathsf{A} & \mathsf{C} \\ \mathsf{0} & \mathsf{I} \\ \end{bmatrix}
Luego su determinante es
\det{(\mathsf{K})} = \det{(\mathsf{A})} \cdot \det{(\mathsf{I})} = \det{(\mathsf{A})} \neq 0 ya que \mathsf{A} es definida positiva por el teorema 3.8.
Observación. Aún cuando la matriz \mathsf{A} sea simétrica, la matriz de rigidez \mathsf{K} (ecuación 3.38) no lo es. Sin embargo, es posible realizar el procedimiento de reemplazar filas por ceros excepto en la diagonal agregando operaciones extra de reemplazo de columnas por ceros excepto en la diagonal mientras al mismo tiempo se realizan operaciones equivalentes sobre el vector \mathbf{f} del miembro derecho de forma tal de obtener un sistema de ecuaciones equivalente donde la matriz sea simétrica. Estos detalles forman parte de la implementación computacional y no de la teoría detrás del método numérico.
Observación. El procedimiento propuesto para obtener la matriz de rigidez no es el único. Otra formas de incorporar las condiciones de Dirichlet a la matriz de rigidez incluyen [5]
- Eliminación directa
- Método de penalidad
- Multiplicadores de Lagrange
De todas maneras, este procedimiento…
- es computacionalmente eficiente (especialmente si se elige la constante \alpha \neq 0 que se pone en la diagonal de las filas de Dirichlet en forma apropiada y se mantiene la simetría de la matriz del sistema de ecuaciones), y
- permite incorporar condiciones de contorno de Dirichlet no homogéneas de una forma muy natural como mostramos a continuación.
En efecto, supongamos ahora que tengamos que resolver el problema de la ecuación 3.26 con una condición de contorno de Dirichlet no homogénea
u(\mathbf{x}) = g(\mathbf{x}) \quad \forall \mathbf{x} \in \Gamma_D
La forma de resolver el problema continuo que introdujimos en la Sección 3.4.1.2 fue considerar u_g \in H_g^1, escribir u_h = u - u_g y encontrar u_h \in V tal que
\mathcal{a}(u_h,v) = \mathcal{B}(v) - \mathcal{a}(u_g,v) \quad \forall v \in V
Ahora,
volvemos a pasar \mathcal{a}(u_g,v) al miembro izquierdo aprovechando la bi-linealidad de a
\mathcal{a}(u_h+u_g,v) = \mathcal{a}(u,v) = \mathcal{B}(v)
escribimos la parte homogénea u_h como
u_h(\mathbf{x}) = \sum_{j=1}^{J} h_j(\mathbf{x}) \cdot u_j + \sum_{j=J+1}^{J+J_D} h_j(\mathbf{x}) \cdot 0 = \tilde{\mathsf{H}} \cdot \begin{bmatrix} \mathbf{u} \\ \mathbf{0} \end{bmatrix}
la función auxiliar u_g que satisface la condición de Dirichlet como
u_g(\mathbf{x}) = \sum_{j=1}^{J} h_j(\mathbf{x}) \cdot 0 + \sum_{j=J+1}^{J+J_D} h_j(\mathbf{x}) \cdot g(\mathbf{x}_j) = \tilde{\mathsf{H}} \cdot \begin{bmatrix} \mathbf{0} \\ \mathbf{g} \end{bmatrix}
y la suma u=u_h+u_g
u(\mathbf{x}) = u_h(\mathbf{x}) + u_g(\mathbf{x}) = \sum_{j=1}^{J} h_j(\mathbf{x}) \cdot u_j + \sum_{j=J+1}^{J+J_D} h_j(\mathbf{x}) \cdot g(\mathbf{x}_j) = \tilde{\mathsf{H}} \cdot \tilde{\mathbf{u}} donde ahora extendemos \mathbf{u} como
\tilde{\mathbf{u}} = \begin{bmatrix} \mathbf{u} \\ \mathbf{g} \end{bmatrix} y
\mathbf{g} = \begin{bmatrix} g(\mathbf{x}_{J+1}) \\ g(\mathbf{x}_{J+2}) \\ \vdots \\ g(\mathbf{x}_{J+J_D}) \\ \end{bmatrix}
Como v(\mathbf{x}) \in V_J \subset H^1_0, entonces \mathbf{v} todavía se extiende con ceros
\tilde{\mathbf{v}} = \begin{bmatrix} \mathbf{v} \\ \mathbf{0} \end{bmatrix} y el problema discretizado queda
\begin{aligned} \begin{bmatrix} \mathbf{v}^T & \mathbf{0}^T \end{bmatrix} \cdot \begin{bmatrix} \mathsf{A} & \mathsf{C} \\ \mathsf{D} & \mathsf{E} \end{bmatrix} \cdot \begin{bmatrix} \mathbf{u} \\ \mathbf{g} \end{bmatrix} &= \begin{bmatrix} \mathbf{v}^T & \mathbf{0}^T \end{bmatrix} \cdot \begin{bmatrix} \mathbf{b} \\ \mathbf{e} \end{bmatrix} \\ \begin{bmatrix} \mathbf{v}^T & \mathbf{0}^T \end{bmatrix} \cdot \begin{bmatrix} \mathsf{A} \cdot \mathbf{u} + \mathsf{C} \cdot \mathbf{g} \\ \mathsf{D} \cdot \mathbf{u} + \mathsf{E} \cdot \mathbf{g} \end{bmatrix} &= \begin{bmatrix} \mathbf{v}^T & \mathbf{0}^T \end{bmatrix} \cdot \begin{bmatrix} \mathbf{b} \\ \mathbf{e} \end{bmatrix} \\ \mathbf{v}^T \cdot \mathsf{A} \cdot \mathbf{u} + \mathbf{v}^T \cdot \mathsf{C} \cdot \mathbf{g} &= \mathbf{v}^T \cdot \mathbf{b} \end{aligned} para todo \mathbf{u} \in \mathbb{R}^J. Es decir, la aproximación de Galerkin para el problema con condiciones de Dirichlet no homogéneas es
\mathsf{A} \cdot \mathbf{u} + \mathsf{C} \cdot \mathbf{g} = \mathbf{b} \tag{3.39}
Corolario 3.11 Sean los objetos
\mathsf{K} = \begin{bmatrix} \mathsf{A} & \mathsf{C} \\ \mathsf{0} & \mathsf{I} \\ \end{bmatrix} \quad \mathbf{f} = \begin{bmatrix} \mathbf{b} \\ \mathbf{g} \\ \end{bmatrix} tales que se satisface la ecuación 3.39, entonces el vector \mathbf{\varphi} tal que \mathsf{K} \cdot \mathbf{\varphi} = \mathbf{f} es igual a
\mathbf{\varphi} = \begin{bmatrix} \mathbf{u} \\ \mathbf{g} \\ \end{bmatrix}
Prueba. Sea \mathbf{\varphi} = \begin{bmatrix} \mathbf{\varphi}_1 & \mathbf{\varphi}_2 \end{bmatrix}^T. Entonces \mathsf{K} \cdot \mathbf{\varphi} es
\begin{bmatrix} \mathsf{A} & \mathsf{C} \\ \mathsf{0} & \mathsf{I} \end{bmatrix} \cdot \begin{bmatrix} \mathbf{\varphi}_1 \\ \mathbf{\varphi}_2 \end{bmatrix} = \begin{bmatrix} \mathsf{A} \cdot \mathbf{\varphi}_1 + \mathsf{C} \cdot \mathbf{\varphi}_2\\ \mathsf{0} \cdot \mathbf{\varphi}_1 + \mathsf{I} \cdot \mathbf{\varphi}_2 \end{bmatrix} = \begin{bmatrix} \mathbf{b}\\ \mathbf{g} \end{bmatrix}
De la segunda fila se tiene \mathbf{\varphi}_2 = \mathbf{g}. Reemplazando este resultado en la primera fila,
\mathsf{A} \cdot \mathbf{\varphi}_1 + \mathsf{C} \cdot \mathbf{g} = \mathbf{b}
Dado que se satisface la ecuación 3.39 entonces \mathbf{\varphi}_1 = \mathbf{u}.
Observación. Los corolarios 3.10 y 3.11 muestran que el procedimiento de reemplazar las filas correspondientes a los puntos de \Gamma_D por ceros excepto un uno (o \alpha \neq 0) en la diagonal y por el valor de la condición de contorno g(\mathbf{x}_j) (o \alpha \cdot g(\mathbf{x}_j)) en dicho punto funciona tanto para condiciones homogéneas como no homogéneas.
Observación. Para el caso no homogéneo, el contenido de la matriz \mathsf{C} que contiene el resultado de aplicar el operador \mathcal{a} entre las funciones de forma del interior de U y de \Gamma_N contra las funciones de forma de \Gamma_D
c_{i,j-J} = \mathcal{a}\left(h_i(\mathbf{x}),h_j(\mathbf{x})\right) \quad \text{para $i=1,\dots,J$ y $j=J+1,J+J_D$}
no es irrelevante como lo era para el caso g(\mathbf{x})=0.
Estamos entonces en condiciones resolver el primero de los dos puntos : ¿cómo encontramos J+J_D funciones de forma apropiadas? Para ello, consideramos la topología subyacente en los J+J_D puntos. Tomemos la figura 3.9, que muestra no sólo los J_D puntos sobre \Gamma_D sino también los triángulos que forman los J+J_D puntos.

Definición 3.20 ((laxa de) elemento) Un elemento es una entidad topológica de dimensión D=0,1,2 o 3 capaz de cubrir un dominio espacial U \in \mathbb{R}^D.
Definición 3.21 (nodo) Llamamos a cada uno de los puntos que define un elemento, nodo.
Definición 3.22 (valor nodal) Dado que h_j(\mathbf{x}_i) = \delta_{ij} entonces los coeficientes v^{(j)} son iguales a la función v evaluada en \mathbf{x}_j, es decir el valor que toma la función en el nodo j
v^{(j)} = v(\mathbf{x}_j)
Llamamos a v^{(j)}, el valor nodal de la solución aproximada.
Observación. Los J valores nodales u_j son las incógnitas que se obtienen al resolver el problema numéricamente. Pero la solución al problema de Galerkin no es simplemente un conjunto de coeficientes sino una función continua u_N(\mathbf{x}) que puede ser evaluada en cualquier punto del espacio \mathbf{x} \in U.
Corolario 3.12 Para que sea posible recuperar exactamente una función constante u(\mathbf{x})= \text{cte} \in U a partir de valores nodales constantes u_j = \text{cte} las funciones de forma deben sumar uno \forall \mathbf{x} \in U. En resumen, las funciones de forma deben cumplir
\begin{cases} h_j(\mathbf{x}_i) = \delta_{ij} &\quad \text{para \quad $j=1,\dots,J+J_D$ \quad e \quad $i=1,\dots,J+J_D$} \\ \displaystyle \sum_{j=1}^{J+J_D} h_j(\mathbf{x}) = 1 &\quad \forall \mathbf{x} \in U ~\text{(incluyendo la frontera $\partial U$)} \end{cases} \tag{3.40}
Si los elementos son apropiados, la integral sobre el dominio U es aproximadamente igual a la suma de las integrales sobre cada uno de los I elementos e_1, e_2, …, e_I en los que lo dividimos. De hecho, los elementos son “apropiados” justamente si a medida que dividimos el dominio en más y más elementos cada vez de menor tamaño (lo que implica que J \rightarrow \infty), entonces
\lim_{I \rightarrow \infty} \sum_{i=1}^I \int_{e_i} f(\mathbf{x}) \, d^D\mathbf{x} = \int_{U} f(\mathbf{x}) \, d^D\mathbf{x} para cualquier función f(\mathbf{x}) : U \mapsto \mathbb{R} integrable.
La idea básica del método de elementos finitos (al menos para problemas lineales) es justamente concentrarse en escribir las integrales que definen la matriz de rigidez y el vector del miembro derecho en cada uno de los elementos e_i para luego “ensamblar” estos objetos globales a partir de las contribuciones elementales. Justamente, este proceso de enfocarse en los elementos es muy eficiente desde del punto de vista computacional ya que se presta perfectamente para ser realizado en forma paralela como mostramos en el capítulo 4.
Para fijar ideas, supongamos por un momento que tenemos el siguiente elemento triangular en el plano x-y:

Consideremos las funciones
\begin{aligned} h_1(\mathbf{x}) &= 1 - x - y \\ h_2(\mathbf{x}) &= x \\ h_3(\mathbf{x}) &= y \\ \end{aligned}
Si el triángulo fuese el dominio U \in \mathbb{R}^2 y quisiéramos resolver una ecuación diferencial en derivadas parciales discretizándolo con los tres nodos \mathbf{x}_1, \mathbf{x}_2 y \mathbf{x}_3 entonces estas funciones de forma cumplirían los requerimientos de la ecuación 3.40. Recordando las ecuaciones 3.35 y 3.36,
\begin{aligned} \tilde{\mathsf{H}}(\mathbf{x}) &= \begin{bmatrix} 1-x-y & x & y \end{bmatrix} \quad \mathbb{R}^{1 \times J}\\ \tilde{\mathsf{B}}(\mathbf{x}) &= \begin{bmatrix} -1 & +1 & 0 \\ -1 & 0 & +1\end{bmatrix} \quad \mathbb{R}^{D \times J} \end{aligned}
Usando las expresiones de la ecuación 3.34, podemos calcular explícitamente la matriz aumentada \tilde{\mathsf{A}} como
\tilde{\mathsf{A}} = \int_e \begin{bmatrix} -1 & -1 \\ +1 & 0 \\ 0 & +1 \\ \end{bmatrix} \cdot k(\mathbf{x}) \cdot \begin{bmatrix} -1 & +1 & 0 \\ -1 & 0 & +1 \end{bmatrix} \, d^D\mathbf{x} \\ = \begin{bmatrix} 2 & -1 & -1 \\ -1 & 1 & 0 \\ -1 & 0 & 1 \\ \end{bmatrix} \cdot \int_e f(\mathbf{x}) \, d^D\mathbf{x} donde e se refiere al elemento triangular. Si f(\mathbf{x})=1, entonces la integral es el área del triángulo, que es 1/2. Lo importante del ejemplo es que la matriz de rigidez elemental
- es cuadrada de tamaño J \times J siendo J el número de nodos del elemento,19 y
- conocidas las funciones de forma del elemento, podemos calcular fácilmente primero derivando las h_j con respecto a las variables espaciales y luego integrando la misma expresión de la matriz extendida global sobre el elemento.
En este caso en particular, dado que las funciones de forma son lineales con respecto a las variables espaciales entonces la matriz \mathsf{B}(\mathbf{x}) es uniforme y puede salir fuera de la integral. Para otras topologías de elementos (por ejemplo cuadrángulos) o para elementos de órdenes superiores (en los que se agregan nodos sobre los lados o sobre el seno del elemento), las funciones de forma tendrán una dependencia más compleja y sus derivadas dependerán de \mathbf{x} por lo que efectivamente habrá que integrar el producto \mathsf{B}^T(\mathbf{x}) k(\mathbf{x}) \mathsf{B}(\mathbf{x}) sobre el triángulo. Si bien en general es posible utilizar cualquier método de cuadratura numérica (incluyendo métodos adaptativos), la forma usual de calcular estas integrales es utilizando el método de integración de Gauss que consiste en disponer de una cantidad pre-fijada Q de pares de pesos \omega_q y puntos espaciales \mathbf{x}_q tales que
\int_e \mathbf{F}(\mathbf{x}) \, d^D \mathbf{x} \approx \sum_{q=1}^Q \omega_q \cdot \mathbf{F}(\mathbf{x}_q) donde el número Q depende de la precisión de la aproximación: mientras mayor sea Q, mayor será la precisión de la integral (y mayor será el costo computacional para calcularla).
Está claro que los elementos triangulares de la figura 3.7 no coinciden con el triángulo canónico de vértices [0,0], [1,0] y [0,1]. Pero podemos suponer que este elemento canónico e_c, cuya matriz elemental ya sabemos calcular, vive en un plano bidimensional \xi-\eta. Si pudiésemos encontrar, para cada elemento real e_i del dominio U, una transformación biyectiva entre las coordenadas reales x-y y las coordenadas canónicas \xi-\eta entonces podríamos calcular por un lado las integrales utilizando el jacobiano \mathsf{J} de la transformación \mathbf{x} \mapsto \mathbf{\xi}
\int_{e_i} f(\mathbf{x}) \, d^2\mathbf{x} = \int_{e_c} f(\mathbf{\xi}) \cdot \Big| \det{(\mathsf{J})} \Big| \, d^2\mathbf{\xi} y por otro las derivadas con respecto a las coordenadas originales x-y que aparezcan en los integrandos utilizando la regla de la cadena
\begin{aligned} \frac{\partial f}{\partial x} &= \frac{\partial f}{\partial \xi} \cdot \frac{\partial \xi}{\partial x} + \frac{\partial f}{\partial \eta} \cdot \frac{\partial \eta}{\partial x} \\ \frac{\partial f}{\partial y} &= \frac{\partial f}{\partial \xi} \cdot \frac{\partial \xi}{\partial y} + \frac{\partial f}{\partial \eta} \cdot \frac{\partial \eta}{\partial y} \\ \end{aligned}
Para ello consideremos la siguiente transformación inversa de \mathbf{\xi} a \mathbf{x}
\begin{aligned} x &= h_1(\mathbf{\xi}) \cdot x_1 + h_2(\mathbf{\xi}) \cdot x_2 + h_3(\mathbf{\xi}) \cdot x_3 = \sum_{j=1}^3 h_j(\mathbf{\xi}) \cdot x_j \\ y &= h_1(\mathbf{\xi}) \cdot y_1 + h_2(\mathbf{\xi}) \cdot y_2 + h_3(\mathbf{\xi}) \cdot y_3 = \sum_{j=1}^3 h_j(\mathbf{\xi}) \cdot y_j \\ \end{aligned} donde x_j e y_j son las coordenadas del nodo j-ésimo del elemento triangular e_i. Es decir, la transformación (inversa) propuesta consiste en interpolar las coordenadas reales continuas \mathbf{x} a partir de las coordenadas reales \mathbf{x}_j de los nodos del elemento real e_i usando las funciones de forma del elemento canónico e_c.20 Las derivadas parciales de x e y con respecto a \xi y \eta son
\begin{aligned} \frac{\partial x}{\partial \xi} &= \sum_{j=1}^3 \frac{\partial h_j}{\partial \xi} \cdot x_j \\ \frac{\partial x}{\partial \eta} &= \sum_{j=1}^3 \frac{\partial h_j}{\partial \eta} \cdot x_j \\ \frac{\partial y}{\partial \xi} &= \sum_{j=1}^3 \frac{\partial h_j}{\partial \xi} \cdot y_j \\ \frac{\partial y}{\partial \eta} &= \sum_{j=1}^3 \frac{\partial h_j}{\partial \eta} \cdot y_j \\ \end{aligned} \tag{3.41}
Los diferenciales dx y dy se relacionan con los diferenciales d\xi y d\eta como
\begin{aligned} dx &= \frac{\partial x}{\partial \xi} \cdot d\xi + \frac{\partial x}{\partial \eta} \cdot d\eta \\ dy &= \frac{\partial y}{\partial \xi} \cdot d\xi + \frac{\partial y}{\partial \eta} \cdot d\eta \\ \end{aligned} que en forma matricial podemos escribir como
\begin{bmatrix} dx \\ dy \end{bmatrix} = \begin{bmatrix} \displaystyle \frac{\partial x}{\partial \xi} & \displaystyle \frac{\partial x}{\partial \eta} \\ \displaystyle \frac{\partial y}{\partial \xi} & \displaystyle \frac{\partial y}{\partial \eta} \end{bmatrix} \cdot \begin{bmatrix} d\xi \\ d\eta \end{bmatrix} = \mathsf{J} \cdot \begin{bmatrix} d\xi \\ d\eta \end{bmatrix} \tag{3.42}
De la misma manera,
\begin{bmatrix} d\xi \\ d\eta \end{bmatrix} = \begin{bmatrix} \displaystyle \frac{\partial \xi}{\partial x} & \displaystyle \frac{\partial \xi}{\partial y} \\ \displaystyle \frac{\partial \eta}{\partial x} & \displaystyle \frac{\partial \eta}{\partial y} \end{bmatrix} \cdot \begin{bmatrix} dx \\ dy \end{bmatrix}
Reemplazando en la ecuación 3.42
\begin{bmatrix} dx \\ dy \end{bmatrix} = \begin{bmatrix} \displaystyle \frac{\partial x}{\partial \xi} & \displaystyle \frac{\partial x}{\partial \eta} \\ \displaystyle \frac{\partial y}{\partial \xi} & \displaystyle \frac{\partial y}{\partial \eta} \end{bmatrix} \cdot \begin{bmatrix} \displaystyle \frac{\partial \xi}{\partial x} & \displaystyle \frac{\partial \xi}{\partial y} \\ \displaystyle \frac{\partial \eta}{\partial x} & \displaystyle \frac{\partial \eta}{\partial y} \end{bmatrix} \cdot \begin{bmatrix} dx \\ dy \end{bmatrix}
Por lo tanto, debe ser
\begin{bmatrix} \displaystyle \frac{\partial x}{\partial \xi} & \displaystyle \frac{\partial x}{\partial \eta} \\ \displaystyle \frac{\partial y}{\partial \xi} & \displaystyle \frac{\partial y}{\partial \eta} \end{bmatrix} \cdot \begin{bmatrix} \displaystyle \frac{\partial \xi}{\partial x} & \displaystyle \frac{\partial \xi}{\partial y} \\ \displaystyle \frac{\partial \eta}{\partial x} & \displaystyle \frac{\partial \eta}{\partial y} \end{bmatrix} = \begin{bmatrix} 1 & 0 \\ 0 & 1 \\ \end{bmatrix} y entonces
\mathsf{J} = \begin{bmatrix} \displaystyle \frac{\partial x}{\partial \xi} & \displaystyle \frac{\partial x}{\partial \eta} \\ \displaystyle \frac{\partial y}{\partial \xi} & \displaystyle \frac{\partial y}{\partial \eta} \end{bmatrix} \quad \mathsf{J}^{-1} = \begin{bmatrix} \displaystyle \frac{\partial \xi}{\partial x} & \displaystyle \frac{\partial \xi}{\partial y} \\ \displaystyle \frac{\partial \eta}{\partial x} & \displaystyle \frac{\partial \eta}{\partial y} \end{bmatrix}
Teorema 3.15 Para que una transformación \mathbf{x} \mapsto \mathbf{\xi} sea biyectiva, es decir haya una correspondencia uno a uno entre \mathbf{x} y \mathbf{\xi}, el determinante del jacobiano \mathsf{J} debe mantener su signo en el dominio de definición de la transformación.
Corolario 3.13 Si la transformación \mathbf{x} \mapsto \mathbf{\xi} es biyectiva, \det{(\mathsf{J})} \neq 0 y \mathsf{J} tiene inversa.
En forma análoga a la ecuación 3.41, en un elemento e_i el gradiente de una función v \in V es
\begin{bmatrix} \displaystyle \frac{\partial v}{\partial x} \\ \displaystyle \frac{\partial v}{\partial y} \end{bmatrix} = \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial x} & \displaystyle \frac{\partial h_2}{\partial x} & \displaystyle \frac{\partial h_3}{\partial x} \\ \displaystyle \frac{\partial h_1}{\partial y} & \displaystyle \frac{\partial h_2}{\partial y} & \displaystyle \frac{\partial h_3}{\partial y} \end{bmatrix} \cdot \begin{bmatrix} v(\mathbf{x_1}) \\ v(\mathbf{x_2}) \\ v(\mathbf{x_3}) \end{bmatrix}
Según la regla de la cadena,
\frac{\partial h_1}{\partial x} = \frac{\partial h_1}{\partial \xi} \cdot \frac{\partial \xi}{\partial x} + \frac{\partial h_1}{\partial \eta} \cdot \frac{\partial \eta}{\partial x} \\ = \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial \xi} & \displaystyle \frac{\partial h_1}{\partial \eta} \end{bmatrix} \cdot \begin{bmatrix} \displaystyle \frac{\partial \xi}{\partial x} \\ \displaystyle \frac{\partial \eta}{\partial x} \end{bmatrix} = \begin{bmatrix} \displaystyle \frac{\partial \xi}{\partial x} & \displaystyle \frac{\partial \eta}{\partial x} \end{bmatrix} \cdot \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial \xi} \\ \displaystyle \frac{\partial h_1}{\partial \eta} \end{bmatrix}
Entonces podemos escribir
\begin{bmatrix} \displaystyle \frac{\partial v}{\partial x} \\ \displaystyle \frac{\partial v}{\partial y} \end{bmatrix} = \begin{bmatrix} \displaystyle \frac{\partial \xi}{\partial x} & \displaystyle \frac{\partial \eta}{\partial x} \\ \displaystyle \frac{\partial \xi}{\partial y} & \displaystyle \frac{\partial \eta}{\partial y} \end{bmatrix} \cdot \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial \xi} & \displaystyle \frac{\partial h_2}{\partial \xi} & \displaystyle \frac{\partial h_3}{\partial \xi} \\ \displaystyle \frac{\partial h_1}{\partial \eta} & \displaystyle \frac{\partial h_2}{\partial \eta} & \displaystyle \frac{\partial h_3}{\partial \eta} \end{bmatrix} \cdot \begin{bmatrix} v(\mathbf{x_1}) \\ v(\mathbf{x_2}) \\ v(\mathbf{x_3}) \end{bmatrix} = \mathsf{J}^{-T}(\mathbf{\xi}) \cdot \mathsf{B}_c(\mathbf{\xi}) \cdot \mathbf{v} \tag{3.43} donde hemos introducido la matriz \mathsf{B}_c del elemento canónico
\mathsf{B}_c(\mathbf{\xi}) = \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial \xi} & \displaystyle \frac{\partial h_2}{\partial \xi} & \displaystyle \frac{\partial h_3}{\partial \xi} \\ \displaystyle \frac{\partial h_1}{\partial \eta} & \displaystyle \frac{\partial h_2}{\partial \eta} & \displaystyle \frac{\partial h_3}{\partial \eta} \end{bmatrix}
tal que
\mathsf{B}(\mathbf{\xi}) = \mathsf{J}^{-T}(\mathbf{\xi}) \cdot \mathsf{B}_c(\mathbf{\xi}) \tag{3.44}
Más aún, consideremos un triángulo en el plano x-y de coordenadas
\mathbf{x}_1 = \begin{bmatrix} x_1 \\ y_1 \end{bmatrix} \quad \mathbf{x}_2 = \begin{bmatrix} x_2 \\ y_2 \end{bmatrix} \quad \mathbf{x}_3 = \begin{bmatrix} x_3 \\ y_3 \end{bmatrix} tal que podamos construir una matriz de coordenadas C
\mathsf{C} = \begin{bmatrix} \mathbf{x}_1 & \mathbf{x}_2 & \mathbf{x}_3 \end{bmatrix} = \begin{bmatrix} x_1 & x_2 & x_3 \\ y_1 & y_2 & y_3 \\ \end{bmatrix}
Entonces las ecuaciones 3.41 escritas en forma matricial quedan
\begin{bmatrix} \displaystyle \frac{\partial x}{\partial \xi} & \displaystyle \frac{\partial x}{\partial \eta} \\ \displaystyle \frac{\partial y}{\partial \xi} & \displaystyle \frac{\partial y}{\partial \eta} \end{bmatrix} = \begin{bmatrix} x_1 & x_2 & x_3 \\ y_1 & y_2 & y_3 \end{bmatrix} \cdot \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial \xi} & \displaystyle \frac{\partial h_1}{\partial \eta} \\ \displaystyle \frac{\partial h_2}{\partial \xi} & \displaystyle \frac{\partial h_2}{\partial \eta} \\ \displaystyle \frac{\partial h_3}{\partial \xi} & \displaystyle \frac{\partial h_3}{\partial \eta} \end{bmatrix}
Es decir, podemos calcular el jacobiano \mathsf{J} de la transformación \mathbf{\xi} \mapsto \mathbf{x} como
\mathsf{J}(\mathbf{\xi}) = \mathsf{C} \cdot \mathsf{B}^T_c(\mathbf{\xi}) \tag{3.45} y
\mathsf{J}^{-T}(\mathbf{\xi}) = \left[ \mathsf{B}_c^T(\mathbf{\xi}) \cdot \mathsf{C}^T\right]^{-1} \tag{3.46} por lo que
\mathsf{B}(\mathbf{\xi}) = \left[ \mathsf{B}_c^T(\mathbf{\xi}) \cdot \mathsf{C}^T\right]^{-1} \cdot \mathsf{B}_c(\mathbf{\xi})
Observación. Si el problema es tri-dimensional, el elemento canónico e_{c_i} es el tetraedro de dimensión D=3 cuyos J_i=4 vértices tienen coordenadas \mathbf{\xi}_1=[0,0,0], \mathbf{\xi}_2=[1,0,0], \mathbf{\xi}_3=[0,1,0] y \mathbf{\xi}_4=[0,0,1]. Entonces
las J_i=4 funciones de forma son
\begin{aligned} h_1(\xi,\eta,\zeta) &= 1 - \xi - \eta - \zeta \\ h_2(\xi,\eta,\zeta) &= \xi\\ h_3(\xi,\eta,\zeta) &= \eta\\ h_4(\xi,\eta,\zeta) &= \zeta \\ \end{aligned}
la transformación \mathbf{\xi} \in \mathbb{R}^3 \mapsto \mathbf{x} \in \mathbb{R}^3 es
\begin{aligned} x &= \sum_{j=1}^4 h_j(\mathbf{\xi}) \cdot x_j \\ y &= \sum_{j=1}^4 h_j(\mathbf{\xi}) \cdot y_j \\ z &= \sum_{j=1}^4 h_j(\mathbf{\xi}) \cdot z_j \\ \end{aligned}
el jacobiano \mathsf{J} \in \mathbb{R}^{3 \times 3} y su inversa \mathsf{J}^{-1} \in \mathbb{R}^{3 \times 3} son
\mathsf{J} = \begin{bmatrix} \displaystyle \frac{\partial x}{\partial \xi} & \displaystyle \frac{\partial x}{\partial \eta} & \displaystyle \frac{\partial x}{\partial \zeta} \\ \displaystyle \frac{\partial y}{\partial \xi} & \displaystyle \frac{\partial y}{\partial \eta} & \displaystyle \frac{\partial y}{\partial \zeta} \\ \displaystyle \frac{\partial z}{\partial \xi} & \displaystyle \frac{\partial z}{\partial \eta} & \displaystyle \frac{\partial z}{\partial \zeta} \end{bmatrix} \quad \mathsf{J}^{-1} = \begin{bmatrix} \displaystyle \frac{\partial \xi}{\partial x} & \displaystyle \frac{\partial \xi}{\partial y} & \displaystyle \frac{\partial \xi}{\partial z} \\ \displaystyle \frac{\partial \eta}{\partial x} & \displaystyle \frac{\partial \eta}{\partial y} & \displaystyle \frac{\partial \eta}{\partial z} \\ \displaystyle \frac{\partial \zeta}{\partial x} & \displaystyle \frac{\partial \zeta}{\partial y} & \displaystyle \frac{\partial \zeta}{\partial z} \end{bmatrix}
la matriz de derivadas canónicas \mathsf{B}_c \in \mathbb{R}^{3 \times 4} es
\mathsf{B}_c(\mathbf{\xi}) = \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial \xi} & \displaystyle \frac{\partial h_2}{\partial \xi} & \displaystyle \frac{\partial h_3}{\partial \xi} & \displaystyle \frac{\partial h_4}{\partial \xi} \\ \displaystyle \frac{\partial h_1}{\partial \eta} & \displaystyle \frac{\partial h_2}{\partial \eta} & \displaystyle \frac{\partial h_3}{\partial \eta} & \displaystyle \frac{\partial h_4}{\partial \eta} \\ \displaystyle \frac{\partial h_1}{\partial \zeta} & \displaystyle \frac{\partial h_2}{\partial \zeta} & \displaystyle \frac{\partial h_3}{\partial \zeta} & \displaystyle \frac{\partial h_4}{\partial \zeta} \end{bmatrix}
la matriz de coordenadas \mathsf{C} \in \mathbb{R}^{3 \times 4} es
\mathsf{C} = \begin{bmatrix} \mathbf{x}_1 & \mathbf{x}_2 & \mathbf{x}_3 & \mathbf{x}_4 \end{bmatrix} = \begin{bmatrix} x_1 & x_2 & x_3 & x_4 \\ y_1 & y_2 & y_3 & y_4 \\ z_1 & z_2 & z_3 & z_4 \end{bmatrix}
pero las relaciones
\begin{aligned} \nabla \mathbf{v} &= \mathsf{J}^{-T} \cdot \mathsf{B}_c \cdot \mathbf{v} &\quad \eqref{eq-gradv-invJT-B_c-v} \\ \mathsf{B} &= \mathsf{J}^{-T} \cdot \mathsf{B}_c &\quad \eqref{eq-B-invJT-B_c} \\ \mathsf{J} &= \mathsf{C} \cdot \mathsf{B}^T_c &\quad \eqref{eq-J-C-B_c} \\ \mathsf{J}^{-T} &= \left[ \mathsf{B}_c^T \cdot \mathsf{C}\right]^{-1} &\quad \eqref{eq-invJT} \\ \mathsf{B} &= \left[ \mathsf{B}_c^T \cdot \mathsf{C}^T\right]^{-1} \cdot \mathsf{B}_c &\quad \eqref{eq-B} \end{aligned} \tag{3.47}
siguen siendo válidas.
Observación. Además de triángulos (tetraedros) se podrían haber utilizado elementos cuadrangulares (hexaédricos, prismáticos o piramidales), cada uno con su correspondiente elemento canónico en el plano \xi-\eta (espacio \xi-\eta-\zeta) y funciones de forma h_j(\mathbf{\xi}) para j=1,\dots,J. Las relaciones matriciales 3.47 seguirían siendo válidas.
Observación. Además de elementos lineales en los que hay un nodo en cada vértice, también existen elementos de órdenes superiores con nodos en los lados y eventualmente en el seno del elemento (figura 3.10).

Observación. Los elementos del jacobiano \mathsf{J} están dados explícitamente por las ecuaciones 3.41. En algún sentido, \mathsf{J} es “fácil” ya que las funciones de forma h_j(\mathbf{\xi}) tienen una dependencia sencilla con \mathbf{\xi}. Por otro lado, los elementos de \mathsf{J}^{-1} no están disponibles directamente ya que, en general, no tenemos una expresión explícita de \mathbf{\xi}(\mathbf{x}) a partir de la cual calcular las derivadas parciales. Para poder evaluar las derivadas parciales de \xi y \eta (y eventualmente \zeta) con respecto a x e y (y eventualmente z) se debe primero calcular el jacobiano “fácil” \mathsf{J} \in \mathbb{R}^{2 \times 2} (eventualmente \mathbb{R}^{3 \times 3}) con la ecuación 3.45, calcular su inversa \mathsf{J}^{-1} explícitamente y luego, de ser necesario, extraer sus elementos uno a uno.
Para un problema de dimensión D, para cada elemento e_i del dominio discretizado U \in \mathbb{R}^D, una vez que conocemos
la topología del elemento e_i
- segmento para D=1
- triángulo o cuadrángulo para D=2
- tetraedro, hexaedro, prisma o pirámide para D=3
las J_i funciones de forma h_j(\mathbf{\xi}) del elemento canónico e_c en el espacio \mathbf{\xi} \in \mathbb{R}^D con las cuales construimos la matriz canónica \mathsf{H}_c
\mathsf{H}_c(\mathbf{\xi}) = \begin{bmatrix}h_1(\mathbf{\xi}) & h_2(\mathbf{\xi}) & \cdots & h_{J_i}(\mathbf{\xi}) \end{bmatrix} \quad \in \mathbb{R}^{1 \times J_i}
las J_i \cdot D derivadas parciales \partial h_j/\partial \xi_d con respecto a las coordenadas \mathbf{\xi} \in \mathbb{R}^D, con las cuales construimos la matriz canónica \mathsf{B}_c
\mathsf{B}_c(\mathbf{\xi}) = \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial \xi} & \displaystyle \frac{\partial h_2}{\partial \xi} & \cdots & \displaystyle \frac{\partial h_{J_i}}{\partial \xi} \\ \displaystyle \frac{\partial h_1}{\partial \eta} & \displaystyle \frac{\partial h_2}{\partial \eta} & \cdots & \displaystyle \frac{\partial h_{J_i}}{\partial \eta} \\ \displaystyle \frac{\partial h_1}{\partial \zeta} & \displaystyle \frac{\partial h_2}{\partial \zeta} & \cdots & \displaystyle \frac{\partial h_{J_i}}{\partial \zeta} \end{bmatrix} \quad \in \mathbb{R}^{D \times J_i}
el conjunto de Q pares de pesos y ubicaciones de puntos de Gauss (\omega_q, \mathbf{\xi}_q) del elemento canónico e_c
las coordenadas reales \mathbf{x}_j \in \mathbb{R}^D de los J_i nodos que definen el elemento real e_i con los que construimos la matriz de coordenadas \mathsf{C}_i del elemento e_i
\mathsf{C}_i = \begin{bmatrix} \mathbf{x}_1 & \mathbf{x}_2 & \cdots & \mathbf{x}_{J_i} \end{bmatrix} = \begin{bmatrix} x_1 & x_2 & \cdots & x_{J_i} \\ y_1 & y_2 & \cdots & y_{J_i} \\ z_1 & z_2 & \cdots & z_{J_i} \\ \end{bmatrix} \quad \in \mathbb{R}^{D \times J_i}
que permite evaluar el i-ésimo jacobiano \mathsf{J}_i(\mathbf{\xi}) como
\mathsf{J}_i(\mathbf{\xi}) = \mathsf{C}_i \cdot \mathsf{B}_c^T(\mathbf{\xi}) \tag{3.48}
y las coordenadas reales \mathbf{x}_q de los Q puntos de Gauss
\begin{aligned} x_q &= \sum_{j=1}^{J_i} h_j(\mathbf{\xi}_q) \cdot x_j \\ y_q &= \sum_{j=1}^{J_i} h_j(\mathbf{\xi}_q) \cdot y_j \\ z_q &= \sum_{j=1}^{J_i} h_j(\mathbf{\xi}_q) \cdot z_j \\ \end{aligned}
necesarias para evaluar k(\mathbf{x}_q) y f(\mathbf{x}_q) dentro de cada término de la suma de la cuadratura numérica,
entonces estamos en condiciones de evaluar la matriz K_i \in \mathbb{R}^{J_i \times J_i} de rigidez elemental correspondiente al elemento e_i para la formulación en elementos finitos21 de la ecuación generalizada de Poisson como
\begin{aligned} \mathsf{K}_i &= \int_{e_i} \mathsf{B}_i^T(\mathbf{x}) \cdot k(\mathbf{x}) \cdot \mathsf{B}_i(\mathbf{x}) \, d^D\mathbf{x} \\ &= \int_{e_c} \mathsf{B}_i^T(\mathbf{\xi}) \cdot k(\mathbf{x}_q) \cdot \mathsf{B}_i(\mathbf{\xi}) \cdot \Big|\det{\left[\mathsf{J}_i \left(\mathbf{\xi}\right)\right]}\Big| \, d^D\mathbf{\xi} \\ &\approx \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \left\{ \mathsf{B}_i^T(\mathbf{\xi}_q) \cdot k(\mathbf{x}_q) \cdot \mathsf{B}_i(\mathbf{\xi}_q) \right\} \\ &\approx \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \left\{ \Big[ \mathsf{J}_i^{-T}\left(\mathbf{\xi}_q\right) \cdot \mathsf{B}_c(\mathbf{\xi}_q) \Big]^T k(\mathbf{x}_q) \Big[ \mathsf{J}^{-T}\left(\mathbf{\xi}_q\right) \cdot \mathsf{B}_c(\mathbf{\xi}_q) \Big] \right\} \\ &\approx \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \left\{ \Big[ \left( \mathsf{B}^T(\mathbf{\xi}_q) \cdot \mathsf{C}_i^T \right)^{-1} \cdot \mathsf{B}_c(\mathbf{\xi}_q) \Big]^T k(\mathbf{x}_q) \Big[ \left( \mathsf{B}_c^T(\mathbf{\xi}_q) \cdot \mathsf{C}_i^T \right)^{-1} \cdot \mathsf{B}_c(\mathbf{\xi}_q) \Big] \right\} \\ \end{aligned}
y la componente volumétrica del vector elemental \mathbf{b}_i como
\begin{aligned} \mathbf{b}_i^{(U)} &= \int_{e_i} \mathsf{H}_c^T(\mathbf{x}) \cdot f(\mathbf{x}) \, d^D\mathbf{x} \\ &= \int_{e_c} \mathsf{H}_c^T(\mathbf{\xi}) \cdot f(\mathbf{x}) \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}\right)\right]}\Big| \, d^D\mathbf{\xi} \\ &\approx \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \left\{ \mathsf{H}_c^T(\mathbf{\xi}_q) \cdot f(\mathbf{x}_q) \right\} \end{aligned}
Definición 3.23 La matriz de rigidez elemental K_i del elemento e_i según la formulación de elementos finitos desarrollada en esta sección es
\mathsf{K}_i \approx \sum_{q=1}^Q \underbrace{\omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big|}_{\text{cuadratura numérica sobre $e_c$}} \underbrace{\left\{ \mathsf{B}_i^T(\mathbf{\xi}_q) \cdot k(\mathbf{x}_q) \cdot \mathsf{B}_i(\mathbf{\xi}_q) \right\}}_{\text{discretización del operador $-\text{div}(k \cdot \nabla u)$}} \tag{3.49} con
la matriz de coordenadas \mathsf{C}_i
\mathsf{C}_i = \begin{bmatrix} \mathbf{x}_1 & \mathbf{x}_2 & \cdots & \mathbf{x}_{J_i} \end{bmatrix} = \begin{bmatrix} x_1 & x_2 & \cdots & x_{J_i} \\ y_1 & y_2 & \cdots & y_{J_i} \\ z_1 & z_2 & \cdots & z_{J_i} \\ \end{bmatrix} \quad \in \mathbb{R}^{D \times J_i}
las coordenadas reales \mathbf{x}_q del punto de gauss q-ésimo
\mathbf{x}_q(\mathbf{\xi}_q) = \begin{bmatrix} \sum_{j=1}^{J_i} h_j(\mathbf{\xi}_q) \cdot x_j \\ \sum_{j=1}^{J_i} h_j(\mathbf{\xi}_q) \cdot y_j \\ \sum_{j=1}^{J_i} h_j(\mathbf{\xi}_q) \cdot z_j \\ \end{bmatrix} = \sum_{j=1}^{J_i} h_j(\mathbf{\xi}_q) \cdot \mathbf{x}_j \quad \in \mathbb{R}^{D} \\ \tag{3.50}
la matriz canónica de funciones de forma \mathsf{H}_c
\mathsf{H}_c(\mathbf{\xi}_q) = \begin{bmatrix} h_1(\mathbf{\xi}_q) & h_2(\mathbf{\xi}_q) & \cdots & h_1(\mathbf{\xi}_q) \end{bmatrix} \quad \in \mathbb{R}^{1 \times J_i}
la matriz canónica de derivadas \mathsf{B}_c
\mathsf{B}_c(\mathbf{\xi}_q) = \begin{bmatrix} \displaystyle \frac{\partial h_1}{\partial \xi} & \displaystyle \frac{\partial h_2}{\partial \xi} & \cdots & \displaystyle \frac{\partial h_{J_i}}{\partial \xi} \\ \displaystyle \frac{\partial h_1}{\partial \eta} & \displaystyle \frac{\partial h_2}{\partial \eta} & \cdots & \displaystyle \frac{\partial h_{J_i}}{\partial \eta} \\ \displaystyle \frac{\partial h_1}{\partial \zeta} & \displaystyle \frac{\partial h_2}{\partial \zeta} & \cdots & \displaystyle \frac{\partial h_{J_i}}{\partial \zeta} \\ \end{bmatrix} \quad \in \mathbb{R}^{D \times J_i}
el jacobiano \mathsf{J}_i del elemento real e_i
\mathsf{J}_i(\mathbf{\xi}_q) = \mathsf{B}_c(\mathbf{\xi}_q) \cdot \mathsf{C}_i \quad \in \mathbb{R}^{D \times D} \tag{3.51}
la matriz de derivadas reales \mathsf{B}_i del elemento real e_i
\mathsf{B}_i(\mathbf{\xi}_q) = \mathsf{J}_i^{-T}(\mathbf{\xi}_q) \cdot \mathsf{B}_c(\mathbf{\xi}_q) = \left[ \mathsf{B}_c^T(\mathbf{\xi}_q) \cdot \mathsf{C}_i^T \right]^{-1} \cdot \mathsf{B}_c(\mathbf{\xi}_q) \quad \in \mathbb{R}^{D \times J_i} \tag{3.52}
Definición 3.24 El vector elemental de fuentes volumétricas \mathbf{b}_i^{(U)} en el elemento e_i es
\mathbf{b}_i^{(U)} \approx \sum_{q=1}^Q \underbrace{\omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big|}_{\text{cuadratura numérica sobre $e_c$}} \underbrace{\left\{\mathsf{H}_c^T(\mathbf{\xi}_q) \cdot f(\mathbf{x}_q)\right\}}_{\text{discretización del miembro derecho $f$}} \tag{3.53}
Observación. Si las funciones de forma son lineales en \mathbf{\xi} entonces \mathsf{B}_i es uniforme y no depende de \mathbf{\xi}. Si además k(\mathbf{x}) es un polinomio de orden menor o igual al orden de integración del conjunto de pesos y ubicaciones de puntos de Gauss de tamaño Q entonces la integración numérica para \mathsf{K}_i es exacta.
Para evaluar las contribuciones de las condiciones de contorno naturales, debemos integrar sobre elementos en la frontera \partial U del dominio U. Esto es, para D=2 debemos integrar sobre elementos tipo segmento que están sobre el plano x-y (pero no necesariamente sobre la recta real). Para D=3 debemos integrar sobre elementos triangulares o cuadrangulares que están en el espacio x-y-z (pero no necesariamente sobre el plano x-y). Hay varias formas de atacar este problema. En esta tesis proponemos introducir una transformación intermedia desde las coordenadas \mathbf{x} \in \mathbb{R}^D hacia un sistema de coordenadas \mathbf{r} \in \mathbb{R}^{D-1}, para luego sí transformar las coordenadas \mathbf{r} a \mathbf{\xi} y realizar la integración. Por ejemplo, si la condición de contorno de Neumann implica integrar sobre un triángulo arbitrario cuyas coordenadas son \mathbf{x}_1, \mathbf{x}_2 y \mathbf{x}_3 \in \mathbb{R}^3 entonces primero encontramos una (de las infinitas) rotaciones \mathbf{x} \in \mathbb{R}^3 \mapsto \mathbf{r} \in \mathbb{R}^{2} para luego transformar \mathbf{r} \in \mathbb{R}^{2} \mapsto \mathbf{\xi} \in \mathbb{R}^{2} y poder usar las matrices del elemento triangular canónico.
Teorema 3.16 La matriz de rotación que lleva el vector \mathbf{a} \in \mathbb{R}^3 al vector \mathbf{b} \in \mathbb{R}^3 es
\mathsf{R} = \mathsf{I} + \mathsf{T} + \frac{1}{1 - \mathbf{a} \cdot \mathbf{b}} \cdot \mathsf{T}^2 donde la matriz \mathsf{T} es
\mathsf{T} = \begin{bmatrix} 0 & -t_3 & +t_2 \\ +t_3 & 0 & -t_1 \\ -t_2 & +t_1 & 0 \end{bmatrix} y \mathbf{t} es producto cruz entre \mathbf{a} y \mathbf{b}
\mathbf{t} = \mathbf{a} \times \mathbf{b}

Lo que queremos es, como ilustramos en la figura 3.11, transformar una de las dos normales \hat{\mathbf{n}} del triángulo
\hat{\mathbf{n}} = \frac{(\mathbf{x}_2 - \mathbf{x}_1) \times (\mathbf{x}_3 - \mathbf{x}_1)}{|| (\mathbf{x}_2 - \mathbf{x}_1) \times (\mathbf{x}_3 - \mathbf{x}_1) ||}
para que coincida con versor normal en la dirección z, \hat{\mathbf{e}}_z = [0,0,1]. Haciendo \mathbf{a} = \hat{\mathbf{n}} y \mathbf{b} = \hat{\mathbf{e}}_z, el vector \mathbf{t} es
\mathbf{t} = \hat{\mathbf{n}} \times \hat{\mathbf{e}}_z = \begin{bmatrix} t_1 \\ t_2 \\ t_3 \end{bmatrix}
Con esto podemos entonces convertir la matriz con las tres coordenadas tridimensionales \mathsf{C}_i \in \mathbb{R}^{3 \times 3} del triángulo original a una de coordenadas bidimensionales \mathsf{C}_i^\prime \in \mathbb{R}^{2 \times 3} como
\begin{aligned} \begin{bmatrix} \mathsf{C}_i^\prime \\ \mathsf{0} \end{bmatrix} & = \mathsf{R} \cdot \mathsf{C}_i \\ \begin{bmatrix} x_1^\prime & x_2^\prime & x_3^\prime \\ y_1^\prime & y_2^\prime & y_3^\prime \\ z_0 & z_0 & z_0 \\ \end{bmatrix} &= \begin{bmatrix} 1 + k \cdot (-t_3^2- t_2^2) & -t_3 + k \cdot (t_1\cdot t_2) & +t_2 + k \cdot (t_1\cdot t_3) \\ +t_3 + k \cdot (t_1\cdot t_2) & 1 + k \cdot (-t_3^2 - t_1^2) & -t_1 + k \cdot (t_2\cdot t_3) \\ -t_2 + k \cdot (t_1\cdot t_3) & +t_1 + k \cdot (t_2\cdot t_3) & 1 + k \cdot (-t_2^2 - t_1^2) \end{bmatrix} \cdot \begin{bmatrix} x_1 & x_2 & x_3 \\ y_1 & y_2 & y_3 \\ z_1 & z_2 & z_3 \end{bmatrix} \end{aligned} para
k = \frac{1}{1- \hat{\mathbf{n}} \cdot \hat{\mathbf{e}}_z} y algún z_0 arbitrario que podemos ignorar. Entonces podemos calcular el jacobiano de un elemento de superficie e_{i^\prime}^{(D-1)} en un problema tridimensional con las funciones de forma tradicionales del triángulo canónico e_{c^\prime}^{(D-1)} cuya matriz de coordenadas \mathsf{C}^\prime_i es \mathsf{C}^\prime_i = \begin{bmatrix} x_1^\prime & x_2^\prime & x_3^\prime \\ y_1^\prime & y_2^\prime & y_3^\prime \\ \end{bmatrix} \quad \in \mathbb{R}^{2 \times 3}
Definición 3.25 La contribución de las condiciones de contorno naturales al vector \mathbf{b}_i es
\begin{aligned} \mathbf{b}_i^{(\Gamma_N)} &= \int_{e_{i^\prime}^{(D-1)}} \mathsf{H}_c^T(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1}\mathbf{x} \\ &= \int_{e_{c^\prime}^{(D-1)}} \mathsf{H}_{c^\prime}^T(\mathbf{\xi}) \cdot p(\mathbf{x}) \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}\right)\right]}\Big| \, d^{D-1}\mathbf{\xi} \\ &\approx \sum_{q=1}^Q \omega_q^{(D-1)} \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \left\{ \mathsf{H}_{c^\prime}^T(\mathbf{\xi}_q) \cdot p(\mathbf{x}_q) \right\} \end{aligned} \tag{3.54} donde la matriz \mathsf{H}_{c^\prime} es la del elemento canónico superficial e_{c^\prime}^{(D-1)} y el jacobiano \mathsf{J}_i es el que le corresponde al elemento superficial e_{i^\prime}^{(D-1)}, ambos de dimensión D-1.
Observación. No tener en cuenta ningún término de superficie es equivalente a hacer que p(\mathbf{x})=0. Es decir, que las condiciones de contorno sean homogéneas en \Gamma_N. Para algunos problemas, como por ejemplo elasticidad, esto no presenta mayores inconvenientes ya que una condición de Neumann homogénea sobre una superficie quiere decir que dicha superficie no tiene ninguna carga externa, que es lo que sucede en caras que están en contacto con “el vacío”. Luego solamente hay que prestar atención a las superficies que tienen condiciones de contorno naturales no homogéneas. Para otros problemas, como por ejemplo conducción de calor o difusión de neutrones, una condición natural homogénea indica una superficie de simetría y no “de vacío”. Hay que prestar especial atención entonces en agregar explícitamente condiciones de contorno no triviales en todas las caras expuestas al vacío, mientras que no hay que hacer nada para las caras con simetría.
3.4.2 Ecuación de difusión de neutrones
Estamos en condiciones entonces de discretizar en espacio las ecuaciones de difusión multigrupo que derivamos en la Sección 3.2
\tag{\ref{eq-difusionmultigrupo}} \begin{gathered} - \text{div} \Big[ D_g(\mathbf{x}) \cdot \text{grad} \left[ \phi_g(\mathbf{x}) \right] \Big] + \Sigma_{t g}(\mathbf{x}) \cdot \phi_g(\mathbf{x}) = \\ \sum_{g^\prime = 1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x}) + \chi_g \sum_{g^\prime = 1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \cdot \phi_{g^\prime}(\mathbf{x})+ s_{0g}(\mathbf{x}) \end{gathered}
Comenzamos con el caso G=1 en la sección que sigue y luego generalizamos la formulación para G>1 en la Sección 3.4.2.2.
3.4.2.1 Un único grupo de energía
Para G=1 la ecuación se simplifica a
- \text{div} \Big[ D(\mathbf{x}) \cdot \text{grad} \left[ \phi(\mathbf{x}) \right] \Big] + \left[\Sigma_{t}(\mathbf{x}) - \Sigma_{s_0}(\mathbf{x}) - \nu\Sigma_{f}(\mathbf{x}) \right]\cdot \phi(\mathbf{x}) = s_{0}(\mathbf{x})
El término de la divergencia y el miembro derecho tienen la misma forma que la ecuación de Poisson que analizamos en la Sección 3.4.1, por lo que debemos esperar contribuciones elementales \mathsf{B}_i^T \cdot D \cdot \mathsf{B}_i y \mathsf{H}_i^T \cdot s_0 respectivamente. Para evaluar el término de fuente neta lineal con \phi procedemos a multiplicar la formulación fuerte por una función de prueba v(\mathbf{x}) \in V22 e integrar en el dominio U\in\mathbb{R}^D
\begin{gathered} \int_U v(\mathbf{x}) \cdot \left\{ - \text{div} \Big[ D(\mathbf{x}) \cdot \text{grad} \left[ \phi(\mathbf{x}) \right] \Big] \right\} \, d^D\mathbf{x} \\ + \int_U v(\mathbf{x}) \cdot \left\{ \left[\Sigma_{t}(\mathbf{x}) - \Sigma_{s_0}(\mathbf{x}) - \nu\Sigma_{f}(\mathbf{x}) \right] \cdot \phi(\mathbf{x}) \right\} \, d^D\mathbf{x} = \int_U v(\mathbf{x}) \cdot s_{0}(\mathbf{x}) \, d^D\mathbf{x} \end{gathered}
Usando la fórmula de Green y el hecho de que v(\mathbf{x})=0 en \Gamma_D obtenemos la formulación débil de la ecuación de difusión para un único grupo de energía
\begin{gathered} \int_U \text{grad} \left[ v(\mathbf{x}) \right] \cdot D(\mathbf{x}) \cdot \text{grad} \left[ \phi(\mathbf{x}) \right] \,d^D\mathbf{x} + \int_U v(\mathbf{x}) \cdot \left[\Sigma_{t}(\mathbf{x}) - \Sigma_{s_0}(\mathbf{x}) - \nu\Sigma_{f}(\mathbf{x}) \right] \cdot \phi(\mathbf{x}) \,d^D\mathbf{x} = \\ \int_U v(\mathbf{x}) \cdot s_0(\mathbf{x}) \,d^D\mathbf{x} + \int_{\Gamma_N} v(\mathbf{x}) \cdot p(\mathbf{x}) \,d^{D-1}\mathbf{x} \end{gathered} donde p(\mathbf{x}) es la condición de contorno de Neumann sobre \Gamma_D
D(\mathbf{x}) \cdot \Big[ \text{grad} \left[ \phi(\mathbf{x}) \right] \cdot \hat{\mathbf{n}} \Big] = p(\mathbf{x})
Observación. Si la frontera \Gamma_D tiene una condición de simetría entonces p(\mathbf{x}) = 0 y las contribuciones superficiales al vector \mathbf{b} son idénticamente cero.
Observación. Si la ecuación de difusión tiene una condición de vacío (definición 2.18) sobre \Gamma_V, entonces
D(\mathbf{x}) \cdot \frac{\partial \phi}{\partial n} = -\frac{1}{2} \cdot \phi(\mathbf{x})
Esto es equivalente a agregar el término de superficie
\int_{\Gamma_V} v(\mathbf{x}) \cdot \frac{1}{2} \cdot \phi(\mathbf{x}) \, d^{D-1}\mathbf{x} \approx \int_{\Gamma_V} \mathbf{v}^T \cdot \mathsf{H}^T(\mathbf{x}) \cdot \frac{1}{2} \cdot \mathsf{H}^T(\mathbf{x}) \cdot \mathbf{\phi} \, d^{D-1}\mathbf{x} al operador \mathcal{a}(\phi, v).
Observación. El operador bi-lineal a(\phi,v) : V \times V \mapsto \mathbb{R} discretizado para este problema es
\begin{aligned} \mathcal{a}(\phi,v) =& \int_U \text{grad}\Big[ v(\mathbf{x}) \Big] D(\mathbf{x}) \text{grad}\Big[ \phi(\mathbf{x}) \Big] \, d^D \mathbf{x} + \int_U v(\mathbf{x}) \left[\Sigma_{t}(\mathbf{x}) - \Sigma_{s_0}(\mathbf{x}) - \nu\Sigma_{f}(\mathbf{x}) \right] \phi(\mathbf{x}) \,d^D\mathbf{x} \\ & \quad \quad + \int_{\Gamma_V} v(\mathbf{x}) \cdot \frac{1}{2} \cdot \phi(\mathbf{x}) \, d^{D-1}\mathbf{x} \\ \approx & \int_U \mathbf{v}^T \mathsf{B}^T(\mathbf{x}) D(\mathbf{x}) \mathsf{B}(\mathbf{x}) \mathbf{\phi} \,\, d^D\mathbf{x} + \int_U \mathbf{v}^T \mathsf{H}^T(\mathbf{x}) \left[\Sigma_{t}(\mathbf{x}) - \Sigma_{s_0}(\mathbf{x}) - \nu\Sigma_{f}(\mathbf{x}) \right] \mathsf{H}(\mathbf{x}) \mathbf{\phi} \,\, d^D\mathbf{x} \\ & \quad\quad \int_{\Gamma_V} \mathbf{v}^T \cdot \mathsf{H}^T(\mathbf{x}) \cdot \frac{1}{2} \cdot \mathsf{H}^T(\mathbf{x}) \cdot \mathbf{\phi} \, d^{D-1}\mathbf{x} \\ =& \mathbf{v}^T \left[ \int_U \mathsf{B}^T(\mathbf{x}) D(\mathbf{x}) \mathsf{B}(\mathbf{x}) \, d^D\mathbf{x} + \int_U \mathsf{H}^T(\mathbf{x}) \left[\Sigma_{t}(\mathbf{x}) - \Sigma_{s_0}(\mathbf{x}) - \nu\Sigma_{f}(\mathbf{x}) \right] \mathsf{H}(\mathbf{x}) \, d^D\mathbf{x} \right. \\ & \quad\quad \left. + \int_{\Gamma_V} \mathsf{H}^T(\mathbf{x}) \cdot \frac{1}{2} \cdot \mathsf{H}^T(\mathbf{x}) \, d^{D-1}\mathbf{x} \right] \mathbf{\phi} \\ \end{aligned} \tag{3.55}
Observación. El operador de la ecuación 3.55 es simétrico.
Observación. El operador de la ecuación 3.55 es coercitivo si \Sigma_{t}(\mathbf{x}) - \Sigma_{s_0}(\mathbf{x}) > \nu\Sigma_{f}(\mathbf{x}). Pero puede dejar de serlo si la desigualdad no se cumple. En efecto, la desigualdad implica k_\text{\infty} < 1. Siguiendo razonamientos físicos, podemos decir que el operador es coercitivo sólo si el factor de multiplicación k_\text{eff} < 1. Esto es, un medio multiplicativo crítico o super-crítico con una fuente independiente no tiene solución de estado estacionario.
Podemos escribir entonces la matriz de rigidez elemental K_i volumétrica del problema de difusión de neutrones a un grupo de energías como
\mathsf{K}_i^{(U)} = \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \left[ \mathsf{L}_i(\mathbf{\xi}_q) + \mathsf{A}_i(\mathbf{\xi}_q) - \mathsf{F}_i(\mathbf{\xi}_q)\right]
donde tenemos la matriz elemental de “pérdidas”23
\mathsf{L}_i = \mathsf{B}_i^T(\mathbf{\xi}_q) \cdot D(\mathbf{\xi}_q) \cdot \mathsf{B}_i^T(\mathbf{\xi}_q) la matriz elemental de absorciones
\mathsf{A}_i = \mathsf{H}_c^T(\mathbf{\xi}_q) \cdot \left[ \Sigma_t(\mathbf{\xi}_q) - \Sigma_{s_0} (\mathbf{\xi}_q) \right] \cdot \mathsf{H}_c(\mathbf{\xi}_q) y la matriz elemental de fisiones
\mathsf{F}_i = \mathsf{H}_c^T(\mathbf{\xi}_q) \cdot \nu\Sigma_f(\mathbf{\xi}_q) \cdot \mathsf{H}_c(\mathbf{\xi}_q)
Observación. El funcional \mathcal{B}(v) : V \mapsto \mathbb{R} es \begin{aligned} \mathcal{B}(v) &= \int_U v(\mathbf{x}) \cdot s_0(\mathbf{x}) \, d^D \mathbf{x} + \int_{\Gamma_N} v(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1} \mathbf{x} \\ &= \int_U \mathbf{v}^T \cdot \mathsf{H}^T(\mathbf{x}) \cdot s_0(\mathbf{x}) \, d^D \mathbf{x} + \int_{\Gamma_N} \mathbf{v}^T \cdot \mathsf{H}^T(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1} \mathbf{x} \\ &= \mathbf{v}^T \cdot \left[ \int_{U} \mathsf{H}^T(\mathbf{x}) \cdot s_0(\mathbf{x}) \, d^D \mathbf{x} + \int_{\Gamma_N} \mathsf{H}^T(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1}\mathbf{x} \right] \end{aligned} \tag{3.56}
Las contribuciones volumétricas y superficiales al vector \mathbf{b}_i son similares al caso del problema de Poisson
\begin{aligned} \mathbf{b}_i^{(U)} &= \int_{e_i} \mathsf{H}^T(\mathbf{x}) \cdot s_0(\mathbf{x}) \, d^D\mathbf{x} \\ &= \int_{e_c} \mathsf{H}^T(\mathbf{\xi}) \cdot s_0(\mathbf{\xi}) \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}\right)\right]}\Big| \, d^D\mathbf{\xi} \\ &\approx \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \mathsf{H}_c^T(\mathbf{\xi}_q) \cdot s_0(\mathbf{\xi}_q) \end{aligned} y \begin{aligned} \mathbf{b}_i^{(\Gamma_N)} &= \int_{e_i^{(D-1)}} \mathsf{H}^T(\mathbf{x}) \cdot p(\mathbf{x}) \, d^{D-1}\mathbf{x} \\ &= \int_{e_c^{(D-1)}} \mathsf{H}^T(\mathbf{\xi}) \cdot p(\mathbf{\xi}) \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}\right)\right]}\Big| \, d^{D-1}\mathbf{\xi} \\ &\approx \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \mathsf{H}^T(\mathbf{\xi}_q) \cdot p(\mathbf{\xi}_q) \end{aligned} respectivamente.
Si existe una frontera \Gamma_V con condición de contorno de vacío, debemos agregar una contribución superficial a la matriz de rigidez
\begin{aligned} K_i^{(\Gamma_V)} &= \int_{e_i^{(D-1)}} \mathsf{H}^T(\mathbf{x}) \cdot \frac{1}{2} \cdot \mathsf{H}(\mathbf{x}) \, d^{D-1}\mathbf{x} \\ &= \int_{e_c^{(D-1)}} \mathsf{H}^T(\mathbf{\xi}) \cdot \frac{1}{2} \cdot \mathsf{H}(\mathbf{\xi}) \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}\right)\right]}\Big| \, d^{D-1}\mathbf{\xi} \\ &\approx \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \mathsf{H}^T(\mathbf{\xi}_q) \cdot \frac{1}{2} \cdot \mathsf{H}(\mathbf{\xi}_q) \end{aligned}
Observación. Para problemas de criticidad, el término de fisiones \mathsf{F}_i no se suma a la matriz de rigidez \mathsf{K}_i sino que forma parte de la matriz de masa \mathsf{M}_i de forma tal de poder escribir las ecuaciones discretizadas como un problema de autovalores
\mathsf{K} \cdot \mathbf{\phi} = \frac{1}{k_\text{eff}} \cdot \mathsf{M} \cdot \mathbf{\phi} En la Sección 3.5.3 discutimos este caso con más detalle.
3.4.2.2 Grupos arbitrarios de energía
Consideremos primeramente caso a dos grupos de energías G=2. La formulación fuerte ahora no es una sino dos ecuaciones diferenciales en derivadas parciales acopladas entre sí a través de los términos de scattering y de fisión
\begin{cases} - \text{div} \left[ D_1 \, \text{grad} \left( \phi_1 \right) \right] + \Sigma_{t1} \phi_1 - \Sigma_{s_0 1 \rightarrow 1} \phi_1 - \Sigma_{s_0 2 \rightarrow 1} \phi_2 - \chi_1 \left[ \nu\Sigma_{f1} \phi_1 + \nu\Sigma_{f2} \phi_2 \right] = s_{0,1} \\ - \text{div} \left[ D_2 \, \text{grad} \left( \phi_2 \right) \right] + \Sigma_{t2} \phi_2 - \Sigma_{s_0 1 \rightarrow 2} \phi_1 - \Sigma_{s_0 2 \rightarrow 2} \phi_2 - \chi_2 \left[ \nu\Sigma_{f1} \phi_1 + \nu\Sigma_{f2} \phi_2 \right] = s_{0,2} \end{cases} que podemos escribir en una única ecuación vectorial como
\begin{gathered} \begin{bmatrix} - \text{div} \left[ D_1(\mathbf{x}) \, \text{grad} \left( \phi_1 \right) \right] \\ - \text{div} \left[ D_2(\mathbf{x}) \, \text{grad} \left( \phi_2 \right) \right] \\ \end{bmatrix} + \begin{bmatrix} \Sigma_{t1}(\mathbf{x}) - \Sigma_{s_0 1 \rightarrow 1}(\mathbf{x}) & - \Sigma_{s_0 2 \rightarrow 1}(\mathbf{x}) \\ - \Sigma_{s_0 1 \rightarrow 2}(\mathbf{x}) & \Sigma_{t2}(\mathbf{x}) - \Sigma_{s_0 2 \rightarrow 2}(\mathbf{x}) \\ \end{bmatrix} \cdot \begin{bmatrix} \phi_1(\mathbf{x}) \\ \phi_2(\mathbf{x}) \\ \end{bmatrix} \\ - \begin{bmatrix} \chi_1 \cdot \nu\Sigma_{f1}(\mathbf{x}) & \chi_1 \cdot \nu\Sigma_{f2}(\mathbf{x}) \\ \chi_2 \cdot \nu\Sigma_{f1}(\mathbf{x}) & \chi_2 \cdot \nu\Sigma_{f2}(\mathbf{x}) \\ \end{bmatrix} \cdot \begin{bmatrix} \phi_1(\mathbf{x}) \\ \phi_2(\mathbf{x}) \\ \end{bmatrix} = \begin{bmatrix} s_{0,1}(\mathbf{x}) \\´ s_{0,2}(\mathbf{x}) \\ \end{bmatrix} \end{gathered}
Introduciendo la matriz \mathsf{R} \in \mathbb{R}^{2 \times 2} de remociones
\mathsf{R}(\mathbf{x}) = \begin{bmatrix} \Sigma_{t1}(\mathbf{x}) & 0 \\ 0 & \Sigma_{t2}(\mathbf{x}) \\ \end{bmatrix} - \begin{bmatrix} \Sigma_{s_0 1 \rightarrow 1}(\mathbf{x}) & \Sigma_{s_0 2 \rightarrow 1}(\mathbf{x}) \\ \Sigma_{s_0 1 \rightarrow 2}(\mathbf{x}) & \Sigma_{s_0 2 \rightarrow 2}(\mathbf{x}) \\ \end{bmatrix} y la matriz \mathsf{X} \in \mathbb{R}^{2 \times 2} de nu-fisiones
\mathsf{X}(\mathbf{x}) = \begin{bmatrix} \chi_1 \cdot \nu\Sigma_{f1}(\mathbf{x}) & \chi_1 \cdot \nu\Sigma_{f2}(\mathbf{x}) \\ \chi_2 \cdot \nu\Sigma_{f1}(\mathbf{x}) & \chi_2 \cdot \nu\Sigma_{f2}(\mathbf{x}) \\ \end{bmatrix} la formulación fuerte para dos grupos de energía G=2 queda
\begin{bmatrix} - \text{div} \left[ D_1(\mathbf{x}) \, \text{grad} \left( \phi_1 \right) \right] \\ - \text{div} \left[ D_2(\mathbf{x})\, \text{grad} \left( \phi_2 \right) \right] \\ \end{bmatrix} + \mathsf{R}(\mathbf{x}) \cdot \begin{bmatrix} \phi_1(\mathbf{x}) \\ \phi_2(\mathbf{x}) \\ \end{bmatrix} - \mathsf{X}(\mathbf{x}) \cdot \begin{bmatrix} \phi_1(\mathbf{x}) \\ \phi_2(\mathbf{x}) \\ \end{bmatrix} = \begin{bmatrix} s_{0,1}(\mathbf{x}) \\ s_{0,2}(\mathbf{x}) \\ \end{bmatrix} más las condiciones de contorno discutidas en la Sección 2.4.5.
Para encontrar la formulación débil multiplicamos cada una de las dos ecuaciones por funciones de prueba (¿flujos escalares virtuales?) v_1(\mathbf{x}) \in V y v_2(\mathbf{x}) \in V respectivamente, las sumamos, integramos en el dominio U \in \mathbb{R}^D y aplicamos la fórmula de Green al término de la divergencia:
\begin{gathered} \int_U \begin{bmatrix} \nabla v_1 & \nabla v_2 \end{bmatrix} \cdot \begin{bmatrix} D_1(\mathbf{x}) & 0 \\ 0 & D_2(\mathbf{x}) \\ \end{bmatrix} \cdot \begin{bmatrix} \nabla \phi_1 \\ \nabla \phi_2 \\ \end{bmatrix} \, d^D\mathbf{x} + \int_U \begin{bmatrix} v_1 & v_2 \end{bmatrix} \cdot \Big[\mathsf{R}(\mathbf{x}) - \mathsf{X}(\mathbf{x})\Big] \cdot \begin{bmatrix} \phi_1(\mathbf{x}) \\ \phi_2(\mathbf{x}) \\ \end{bmatrix} \, d^D\mathbf{x} \\ = \int_U \begin{bmatrix} v_1 & v_2 \end{bmatrix} \cdot \begin{bmatrix} s_{0,1}(\mathbf{x}) \\ s_{0,2}(\mathbf{x}) \\ \end{bmatrix} \, d^D\mathbf{x} + \int_{\Gamma_D} \begin{bmatrix} v_1 & v_2 \end{bmatrix} \cdot \begin{bmatrix} p_1(\mathbf{x}) \\ p_2(\mathbf{x}) \\ \end{bmatrix} \, d^{D-1}\mathbf{x} \end{gathered}
Ahora tratamos de encontrar la aproximación de Galerkin. Para ello, definimos un vector \mathbf{v} \in \mathbb{R}^{GJ} con los valores nodales de v_1(\mathbf{x}) para g=1 y v_2(\mathbf{x}) para g=2 intercalados
\mathbf{v} = \begin{bmatrix} v_1(\mathbf{x}_1) \\ v_2(\mathbf{x}_1) \\ v_1(\mathbf{x}_2) \\ v_2(\mathbf{x}_2) \\ \vdots \\ v_1(\mathbf{x}_{J}) \\ v_2(\mathbf{x}_{J}) \\ \end{bmatrix}
Entonces
\begin{bmatrix} v_1(\mathbf{x}) \\ v_2(\mathbf{x}) \end{bmatrix} = \mathsf{H}_2(\mathbf{x}) \cdot \mathbf{v} donde llamamos \mathsf{H}_2 a la matriz de funciones de forma para G=2
\mathsf{H}_2(\mathbf{x}) = \begin{bmatrix} h_1(\mathbf{x}) & 0 & h_2(\mathbf{x}) & 0 & \cdots & h_{J_i}(\mathbf{x}) & 0 \\ 0 & h_1(\mathbf{x}) & 0 & h_2(\mathbf{x}) & \cdots & 0 & h_{J_i}(\mathbf{x}) \\ \end{bmatrix} \quad \in \mathbb{R}^{2 \times 2J} como un caso particular de la matriz de funciones de forma \mathsf{H}_G para G grupos de energía. De la misma manera, si
\mathbf{\phi} = \begin{bmatrix} \phi_1(\mathbf{x}_1) \\ \phi_2(\mathbf{x}_1) \\ \phi_1(\mathbf{x}_2) \\ \phi_2(\mathbf{x}_2) \\ \vdots \\ \phi_1(\mathbf{x}_{J}) \\ \phi_2(\mathbf{x}_{J}) \\ \end{bmatrix} entonces
\begin{bmatrix} \phi_1(\mathbf{x}) \\ \phi_2(\mathbf{x}) \end{bmatrix} = \mathsf{H}_2(\mathbf{x}) \cdot \mathbf{\phi} y el término de remociones menos fisiones queda
\int_U \begin{bmatrix} v_1 & v_2 \end{bmatrix} \cdot \Big[\mathsf{R}(\mathbf{x}) - \mathsf{X}(\mathbf{x})\Big] \cdot \begin{bmatrix} \phi_1(\mathbf{x}) \\ \phi_2(\mathbf{x}) \\ \end{bmatrix} \, d^D\mathbf{x} = \mathbf{v}^T \cdot \left[ \int_U \mathsf{H}_2^T(\mathbf{x}) \cdot \Big[\mathsf{R}(\mathbf{x}) - \mathsf{X}(\mathbf{x})\Big] \cdot \mathsf{H}_2(\mathbf{x}) \, d^D\mathbf{x} \right] \cdot \mathbf{\phi} \tag{3.57}
Análogamente, el término de fuentes volumétricas del miembro derecho queda
\int_U \begin{bmatrix} v_1 & v_2 \end{bmatrix} \cdot \begin{bmatrix} s_{0,1}(\mathbf{x}) \\ s_{0,2}(\mathbf{x}) \\ \end{bmatrix} \, d^D\mathbf{x} = \mathbf{v}^T \cdot \left[ \int_U \mathsf{H}_2^T(\mathbf{x}) \cdot \begin{bmatrix} s_{0,1}(\mathbf{x}) \\ s_{0,2}(\mathbf{x}) \\ \end{bmatrix} \, d^D\mathbf{x} \right] \tag{3.58} el de condiciones de contorno de Neumann
\int_{\Gamma_N} \begin{bmatrix} v_1 & v_2 \end{bmatrix} \cdot \begin{bmatrix} p_1(\mathbf{x}) \\ p_2(\mathbf{x}) \\ \end{bmatrix} \, d^{D-1}\mathbf{x} = \mathbf{v}^T \cdot \left[ \int_{\Gamma_N} \mathsf{H}_2^T(\mathbf{x}) \cdot \begin{bmatrix} p_1(\mathbf{x}) \\ p_2(\mathbf{x}) \\ \end{bmatrix} \, d^{D-1}\mathbf{x} \right] \tag{3.59} y de condiciones de vacío
\int_{\Gamma_V} \begin{bmatrix} v_1 & v_2 \end{bmatrix} \cdot \frac{1}{2} \cdot \begin{bmatrix} \phi_1(\mathbf{x}) \\ \phi_2(\mathbf{x}) \\ \end{bmatrix} \, d^{D-1}\mathbf{x} = \mathbf{v}^T \cdot \left[ \int_{\Gamma_V} \mathsf{H}_2^T(\mathbf{x}) \cdot \frac{1}{2} \cdot \mathsf{H}_2(\mathbf{x}) \, d^{D-1}\mathbf{x} \right] \tag{3.60}
Nos queda evaluar el término de pérdidas. Para ello, simplifiquemos primera la notación suponiendo un problema bi-dimensional D=2. Por un lado notamos que
\begin{aligned} \begin{bmatrix} \nabla v_1 & \nabla v_2 \end{bmatrix} \cdot \begin{bmatrix} D_1(\mathbf{x}) & 0 \\ 0 & D_2(\mathbf{x}) \\ \end{bmatrix} \cdot \begin{bmatrix} \nabla \phi_1 \\ \nabla \phi_2 \\ \end{bmatrix} =& \frac{\partial v_1}{\partial x} \cdot D_1 \cdot \frac{\partial \phi_1}{\partial x} + \frac{\partial v_2}{\partial x} \cdot D_2 \cdot \frac{\partial \phi_2}{\partial x} \\ &~ + \frac{\partial v_1}{\partial y} \cdot D_1 \cdot \frac{\partial \phi_1}{\partial y} + \frac{\partial v_2}{\partial y} \cdot D_2 \cdot \frac{\partial \phi_2}{\partial y} \\ =& \begin{bmatrix} \frac{\partial v_1}{\partial x} & \frac{\partial v_2}{\partial x} & \frac{\partial v_1}{\partial y} & \frac{\partial v_2}{\partial y} \end{bmatrix} \begin{bmatrix} D_1 & 0 & 0 & 0 \\ 0 & D_2 & 0 & 0 \\ 0 & 0 & D_1 & 0 \\ 0 & 0 & 0 & D_2 \\ \end{bmatrix} \begin{bmatrix} \frac{\partial \phi_1}{\partial x} \\ \frac{\partial \phi_2}{\partial x} \\ \frac{\partial \phi_1}{\partial y} \\ \frac{\partial \phi_2}{\partial y} \end{bmatrix} \end{aligned} y por el otro que
\begin{bmatrix} \frac{\partial v_1}{\partial x} \\ \frac{\partial v_2}{\partial x} \\ \frac{\partial v_1}{\partial y} \\ \frac{\partial v_2}{\partial y} \end{bmatrix} = \mathsf{B}_2(\mathbf{x}) \cdot \mathbf{v} \quad\quad\quad \begin{bmatrix} \frac{\partial \phi_1}{\partial x} \\ \frac{\partial \phi_2}{\partial x} \\ \frac{\partial \phi_1}{\partial y} \\ \frac{\partial \phi_2}{\partial y} \end{bmatrix} = \mathsf{B}_2(\mathbf{x}) \cdot \mathbf{\phi} con
\mathsf{B}_2(\mathbf{x}) = \begin{bmatrix} \frac{\partial h_1}{\partial x} & 0 & \frac{\partial h_2}{\partial x} & 0 & \cdots & \frac{\partial h_j}{\partial x} & 0 \\ 0 & \frac{\partial h_1}{\partial x} & 0 & \frac{\partial h_2}{\partial x} & \cdots & 0 & \frac{\partial h_j}{\partial x} \\ \frac{\partial h_1}{\partial y} & 0 & \frac{\partial h_2}{\partial y} & 0 & \cdots & \frac{\partial h_j}{\partial y} & 0 \\ 0 & \frac{\partial h_1}{\partial y} & 0 & \frac{\partial h_2}{\partial y} & \cdots & 0 & \frac{\partial h_j}{\partial y} \\ \frac{\partial h_1}{\partial z} & 0 & \frac{\partial h_2}{\partial z} & 0 & \cdots & \frac{\partial h_j}{\partial z} & 0 \\ 0 & \frac{\partial h_1}{\partial z} & 0 & \frac{\partial h_2}{\partial z} & \cdots & 0 & \frac{\partial h_j}{\partial z} \\ \end{bmatrix} \quad \in \mathbb{R}^{2D \times 2J} entonces
\int_U \begin{bmatrix} \nabla v_1 & \nabla v_2 \end{bmatrix} \cdot \begin{bmatrix} D_1(\mathbf{x}) & 0 \\ 0 & D_2(\mathbf{x}) \\ \end{bmatrix} \cdot \begin{bmatrix} \nabla \phi_1 \\ \nabla \phi_2 \\ \end{bmatrix} \, d^D\mathbf{x} = \mathbf{v}^T \cdot \left[ \int_U \mathsf{B}_2^T(\mathbf{x}) \cdot \mathsf{D}^{\prime}(\mathbf{x}) \cdot \mathsf{B}_2(\mathbf{x}) \, d^D\mathbf{x} \right] \cdot \mathbf{\phi} \tag{3.61}
siendo la matriz diagonal \mathsf{D} \in \mathbb{R}^{2 \times 2}
\mathsf{D}(\mathbf{x}) = \begin{bmatrix} D_1(\mathbf{x}) & 0 \\ 0 & D_2(\mathbf{x}) \\ \end{bmatrix}
y construyendo la matriz bloque-diagonal \mathsf{D}_{D} según la dimensión D del dominio U
\mathsf{D}_1 (\mathbf{x}) = \mathsf{D}(\mathbf{x}) = \begin{bmatrix} D_1(\mathbf{x}) & 0 \\ 0 & D_2(\mathbf{x}) \\ \end{bmatrix}
\mathsf{D}_2 (\mathbf{x}) = \begin{bmatrix} \mathsf{D}(\mathbf{x}) & \mathsf{0} \\ \mathsf{0} & \mathsf{D}(\mathbf{x}) \\ \end{bmatrix} = \begin{bmatrix} D_1(\mathbf{x}) & 0 & 0 & 0 \\ 0 & D_2(\mathbf{x}) & 0 & 0 \\ 0 & 0 & D_1(\mathbf{x}) & 0 \\ 0 & 0 & 0 & D_2(\mathbf{x}) \\ \end{bmatrix}
\mathsf{D}_3 (\mathbf{x}) = \begin{bmatrix} \mathsf{D}(\mathbf{x}) & \mathsf{0} & \mathsf{0} \\ \mathsf{0} & \mathsf{D}(\mathbf{x}) & \mathsf{0} \\ \mathsf{0} & \mathsf{0} & \mathsf{D}(\mathbf{x}) \\ \end{bmatrix} = \begin{bmatrix} D_1(\mathbf{x}) & 0 & 0 & 0 & 0 & 0\\ 0 & D_2(\mathbf{x}) & 0 & 0 & 0 & 0\\ 0 & 0 & D_1(\mathbf{x}) & 0 & 0 & 0\\ 0 & 0 & 0 & D_2(\mathbf{x}) & 0 & 0\\ 0 & 0 & 0 & 0 & D_1(\mathbf{x}) & 0 \\ 0 & 0 & 0 & 0 & 0 & D_2(\mathbf{x}) \\ \end{bmatrix}
Juntando las ecuaciones
- 3.57 (remociones menos fisiones)
- 3.58 (fuentes independientes)
- 3.59 (condiciones de Neumann)
- 3.60 (condiciones de vacío)
- 3.61 (pérdidas)
el problema de Galerkin para difusión de neutrones a G=2 grupos es encontrar \mathbf{\phi} \in \mathbb{R}^{2J} tal que
\begin{gathered} \mathbf{v}^T \left[ \int_U \Big\{ \mathsf{B}_2^T(\mathbf{x}) \mathsf{D}^{\prime}(\mathbf{x}) \mathsf{B}_2(\mathbf{x}) + \mathsf{H}_2^T(\mathbf{x}) \left[ \mathsf{R}(\mathbf{x})-\mathsf{F}(\mathbf{x})\right] \mathsf{H}_2(\mathbf{x}) \Big\} \, d^D\mathbf{x} + \int_{\Gamma_V} \mathsf{H}_2^T(\mathbf{x}) \frac{1}{2} \mathsf{H}_2(\mathbf{x}) \, d^{D-1}\mathbf{x} \right] \mathbf{\phi} \\ = \mathbf{v}^T \cdot \left[ \int_U \mathsf{H}_2^T \cdot \begin{bmatrix} s_{0,1}(\mathbf{x}) \\ s_{0,2}(\mathbf{x}) \\ \end{bmatrix} \, d^D\mathbf{x} + \int_{\Gamma_N} \mathsf{H}_2^T \cdot \begin{bmatrix} p_1(\mathbf{x}) \\ p_2(\mathbf{x}) \\ \end{bmatrix} \, d^{D-1}\mathbf{x} \right] \end{gathered} para todo \mathbf{v}\in \mathbb{R}^{2J}.
Luego, para el caso general de G grupos de energía sobre un dominio de dimensión D, podemos escribir la matriz de rigidez elemental \mathsf{K}_i como \begin{aligned} \mathsf{K}_i &= \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \left[ \mathsf{L}_i(\mathbf{\xi}_q) + \mathsf{A}_i(\mathbf{\xi}_q) - \mathsf{F}_i(\mathbf{\xi}_q)\right] \end{aligned} \tag{3.62}
a partir de las matrices elementales de pérdidas, absorciones y fisiones de tamaño GJ \times GJ
\begin{aligned} \mathsf{L}_i &= \mathsf{B}_{Gi}^T(\mathbf{\xi}_q) \cdot \mathsf{D}_D(\mathbf{\xi}_q) \cdot \mathsf{B}_{Gi}(\mathbf{\xi}_q) \\ \mathsf{A}_i &= \mathsf{H}_{Gc}^T(\mathbf{\xi}_q) \cdot \mathsf{R}(\mathbf{\xi}_q) \cdot \mathsf{H}_{Gc}(\mathbf{\xi}_q) \\ \mathsf{F}_i &= \mathsf{H}_{Gc}^T(\mathbf{\xi}_q) \cdot \mathsf{X}(\mathbf{\xi}_q) \cdot \mathsf{H}_{Gc}(\mathbf{\xi}_q) \end{aligned} \tag{3.63} donde tenemos ahora la matriz \mathsf{H}_{Gc} \in \mathbb{R}^{G \times GJ} de funciones de forma canónica para G grados de libertad por nodo
\setcounter{MaxMatrixCols}{13} \mathsf{H}_{Gc}(\mathbf{\xi}) = \begin{bmatrix} h_1(\mathbf{\xi}) & 0 & \cdots & 0 & h_2(\mathbf{\xi}) & 0 & \cdots & 0 & \cdots & h_{J_i}(\mathbf{\xi}) & 0 & \cdots & 0 \\ 0 & h_1(\mathbf{\xi}) & \cdots & 0 & 0 & h_2(\mathbf{\xi}) & \cdots & 0 & \cdots & 0 & h_{J_i}(\mathbf{\xi}) & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots & \vdots & \ddots & \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & h_1(\mathbf{\xi}) & 0 & 0 & \cdots & h_2(\mathbf{\xi}) & \cdots & 0 & 0 & \cdots & h_{J_i}(\mathbf{\xi}) \end{bmatrix} y la matriz de derivadas reales \mathsf{B}_{Gi} \in \mathbb{R}^{GD \times GJ_i}
\mathsf{B}_{Gi}(\mathbf{\xi}) = \begin{bmatrix} \frac{\partial h_1}{\partial x} & 0 & \cdots & 0 & \frac{\partial h_2}{\partial x} & 0 & \cdots & 0 & \cdots & \frac{\partial h_{J_i}}{\partial x} & 0 & \cdots & 0 \\ 0 & \frac{\partial h_1}{\partial x} & \cdots & 0 & 0 & \frac{\partial h_2}{\partial x} & \cdots & 0 & \cdots & 0 & \frac{\partial h_{J_i}}{\partial x} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots & \vdots & \ddots & \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \frac{\partial h_1}{\partial x} & 0 & 0 & \cdots & \frac{\partial h_2}{\partial x} & \cdots & 0 & 0 & \cdots & \frac{\partial h_{J_i}}{\partial x} \\ \frac{\partial h_1}{\partial y} & 0 & \cdots & 0 & \frac{\partial h_2}{\partial y} & 0 & \cdots & 0 & \cdots & \frac{\partial h_{J_i}}{\partial y} & 0 & \cdots & 0 \\ 0 & \frac{\partial h_1}{\partial y} & \cdots & 0 & 0 & \frac{\partial h_2}{\partial y} & \cdots & 0 & \cdots & 0 & \frac{\partial h_{J_i}}{\partial y} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots & \vdots & \ddots & \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \frac{\partial h_1}{\partial y} & 0 & 0 & \cdots & \frac{\partial h_2}{\partial y} & \cdots & 0 & 0 & \cdots & \frac{\partial h_{J_i}}{\partial y} \\ \frac{\partial h_1}{\partial z} & 0 & \cdots & 0 & \frac{\partial h_2}{\partial z} & 0 & \cdots & 0 & \cdots & \frac{\partial h_{J_i}}{\partial z} & 0 & \cdots & 0 \\ 0 & \frac{\partial h_1}{\partial z} & \cdots & 0 & 0 & \frac{\partial h_2}{\partial z} & \cdots & 0 & \cdots & 0 & \frac{\partial h_{J_i}}{\partial z} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots & \vdots & \ddots & \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \frac{\partial h_1}{\partial z} & 0 & 0 & \cdots & \frac{\partial h_2}{\partial z} & \cdots & 0 & 0 & \cdots & \frac{\partial h_{J_i}}{\partial z} \\ \end{bmatrix} con las matrices de secciones eficaces macroscópicas de difusión, remoción y nu-fisión
\begin{aligned} \mathsf{D}(\mathbf{x}) &= \begin{bmatrix} D_1(\mathbf{x}) & 0 & \cdots & 0 \\ 0 & D_2(\mathbf{x}) & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & D_G(\mathbf{x}) \end{bmatrix} \in \mathbb{R}^{G \times G} \\ \mathsf{D}_D(\mathbf{x}) &= \begin{bmatrix} \mathsf{D}(\mathbf{x}) & \mathsf{0} & \cdots & \mathsf{0} \\ \mathsf{0} & \mathsf{D}(\mathbf{x}) & \cdots & \mathsf{0} \\ \vdots & \vdots & \ddots & \vdots \\ \mathsf{0} & \mathsf{0} & \cdots & \mathsf{D}(\mathbf{x}) \end{bmatrix} \in \mathbb{R}^{GD \times GD} \\ \mathsf{R} &= \begin{bmatrix} \Sigma_{t1}(\mathbf{x}) & 0 & \cdots & 0 \\ 0 & \Sigma_{t2}(\mathbf{x}) & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \Sigma_{tG}(\mathbf{x}) \end{bmatrix} - \begin{bmatrix} \Sigma_{s_0 1 \rightarrow 1}(\mathbf{x}) & \Sigma_{s_0 2 \rightarrow 1} & \cdots & \Sigma_{s_0 G \rightarrow 1} \\ \Sigma_{s_0 1 \rightarrow 2}(\mathbf{x}) & \Sigma_{s_0 2 \rightarrow 2} & \cdots & \Sigma_{s_0 G \rightarrow 2} \\ \vdots & \vdots & \ddots & \vdots \\ \Sigma_{s_0 1 \rightarrow G}(\mathbf{x}) & \Sigma_{s_0 2 \rightarrow G} & \cdots & \Sigma_{s_0 G \rightarrow G} \\ \end{bmatrix} \in \mathbb{R}^{G \times G} \\ \mathsf{X} &= \begin{bmatrix} \chi_1 \cdot \nu\Sigma_{f1}(\mathbf{x}) & \chi_1 \cdot \nu\Sigma_{f2}(\mathbf{x}) & \cdots & \chi_1 \cdot \nu\Sigma_{fG}(\mathbf{x}) \\ \chi_2 \cdot \nu\Sigma_{f1}(\mathbf{x}) & \chi_2 \cdot \nu\Sigma_{f2}(\mathbf{x}) & \cdots & \chi_2 \cdot \nu\Sigma_{fG}(\mathbf{x}) \\ \vdots & \vdots & \ddots & \vdots \\ \chi_G \cdot \nu\Sigma_{f1}(\mathbf{x}) & \chi_G \cdot \nu\Sigma_{f2}(\mathbf{x}) & \cdots & \chi_G \cdot \nu\Sigma_{fG}(\mathbf{x}) \\ \end{bmatrix} \in \mathbb{R}^{G \times G} \end{aligned}
Observación. El operador bi-lineal \mathcal{a}\big([\phi_1~\dots~\phi_G]^T, [v_1~\dots~v_G]\big) : V^G \times V^G \mapsto \mathbb{R} para G>1 es
\begin{aligned} \mathcal{a}\big([\phi_1~\dots~\phi_G]^T, [v_1~\dots~v_G]^T\big) =& \int_U \text{grad}\Big[ v(\mathbf{x}) \Big] \cdot \mathsf{D}^\prime(\mathbf{x}) \cdot \text{grad}\Big[ \phi(\mathbf{x}) \Big] \, d^D \mathbf{x} \\ & \quad + \int_U v(\mathbf{x}) \cdot \left[\mathsf{R}(\mathbf{x}) - \mathsf{X}(\mathbf{x}) \right] \cdot \phi(\mathbf{x}) \,d^D\mathbf{x} \\ & \quad + \int_{\Gamma_V} v(\mathbf{x}) \cdot \frac{1}{2} \cdot \phi(\mathbf{x}) \,d^{D-1}\mathbf{x} \\ =& \int_U \mathbf{v}^T \cdot \mathsf{B}^T(\mathbf{x}) \cdot \mathsf{D}^\prime(\mathbf{x}) \cdot \mathsf{B}(\mathbf{x}) \cdot \mathbf{u} \,\, d^D\mathbf{x} \\ & \quad + \int_U \mathbf{v}^T \cdot \mathsf{H}^T(\mathbf{x}) \cdot \left[\mathsf{R}(\mathbf{x}) - \mathsf{X}(\mathbf{x}) \right] \cdot \mathsf{H}(\mathbf{x}) \cdot \mathbf{\phi} \, d^D\mathbf{x} \\ & \quad + \int_{\Gamma_V} \mathbf{v}^T \cdot \mathsf{H}^T(\mathbf{x}) \cdot \frac{1}{2} \cdot \mathsf{H}(\mathbf{x}) \cdot \mathbf{\phi} \, d^{D-1}\mathbf{x} \\ =& \mathbf{v}^T \cdot \left[ \int_U \mathsf{B}^T(\mathbf{x}) \cdot \mathsf{D}^\prime(\mathbf{x}) \cdot \mathsf{B}(\mathbf{x}) \, d^D\mathbf{x} \right. \\ & \quad\quad + \int_U \mathsf{H}^T(\mathbf{x}) \cdot \left[\mathsf{R}(\mathbf{x}) - \mathsf{X}(\mathbf{x}) \right] \cdot \mathsf{H}(\mathbf{x}) \, d^D\mathbf{x} \\ & \quad\quad\quad + \left. \int_{\Gamma_V} \mathsf{H}^T(\mathbf{x}) \cdot \frac{1}{2} \cdot \mathsf{H}(\mathbf{x}) \, d^{D-1}\mathbf{x} \right] \cdot \mathbf{\phi} \end{aligned} \tag{3.64}
Observación. El operador de la ecuación 3.64 es simétrico sólo si ambas matrices \mathsf{R} y \mathsf{X} también lo son.
Observación. Las matrices \mathsf{R} y \mathsf{X} no son simétricas para propiedades nucleares reales.
Observación. El operador de la ecuación 3.64 es coercitivo sólo si k_\text{eff} < 1.
Observación. Las matrices \mathsf{H}_{Gc} y \mathsf{B}_{Gi} que “saben” (decimos que son G-aware) cuántos grupos de energía tiene el problema se construyen a partir de las matrices del problema escalar \mathsf{H}_c y \mathsf{B}_i como
\mathsf{H}_{Gc}\Big(g, G \cdot (j-1) + g\Big) = H_c(1,j) = h_j(\mathbf{\xi}) \mathsf{B}_{Gi}\Big(G\cdot (d-1) + g, G\cdot (j-1) + g\Big) = B_c(d,j) = \frac{\partial h_j}{\partial \xi_d} \\ para j=1,\dots,J, g=1,\dots,G, y d=1,\dots,D. El resto de los elementos son cero.
Observación. Para G=1,
\mathsf{H}_{1c} = \mathsf{H}_c \quad \text{y} \quad \mathsf{B}_{1i} = \mathsf{B}_c
Observación. La forma de las matrices G-aware puede ser diferente para otros problemas vectoriales con el mismo número de grados de libertad. Por ejemplo, para el problema de elasticidad tridimensional basado en desplazamientos, G=3 pero la matriz B_{3i} es (ver [2], tabla 6.6)
\mathsf{B}_{3i} = \begin{bmatrix} \frac{\partial h_1}{\partial x} & 0 & 0 & \frac{\partial h_2}{\partial x} & 0 & 0 & \cdots & \frac{\partial h_{J_i}}{\partial x} & 0 & 0 & \\ 0 & \frac{\partial h_1}{\partial y} & 0 & 0 & \frac{\partial h_2}{\partial y} & 0 & \cdots & 0 & \frac{\partial h_{J_i}}{\partial y} & 0 & \\ 0 & 0 & \frac{\partial h_1}{\partial z} & 0 & 0 & \frac{\partial h_2}{\partial z} & \cdots & 0 & 0 & \frac{\partial h_{J_i}}{\partial z} & \\ \frac{\partial h_1}{\partial y} & \frac{\partial h_1}{\partial x} & 0 & \frac{\partial h_2}{\partial y} & \frac{\partial h_2}{\partial x} & 0 & \cdots & \frac{\partial h_{J_i}}{\partial y} & \frac{\partial h_{J_i}}{\partial x} & 0 \\ 0 & \frac{\partial h_1}{\partial z} & \frac{\partial h_1}{\partial y} & 0 & \frac{\partial h_2}{\partial z} & \frac{\partial h_2}{\partial y} & \cdots & 0 & \frac{\partial h_{J_i}}{\partial z} & \frac{\partial h_{J_i}}{\partial y} \\ \frac{\partial h_1}{\partial z} & 0 & \frac{\partial h_1}{\partial x} & \frac{\partial h_2}{\partial z} & 0 & \frac{\partial h_2}{\partial x} & \cdots & \frac{\partial h_{J_i}}{\partial z} & 0 & \frac{\partial h_{J_i}}{\partial x} \\ \end{bmatrix} ya que la matriz equivalente a la \mathsf{D}_G del problema de difusión es de tamaño 6\times 6 con tres filas para las tensiones normales y tres filas para los esfuerzos de corte en una notación de Voigt.
3.4.3 Ordenadas discretas multigrupo
Siguiendo el mismo razonamiento que en la sección anterior, para el caso de ordenadas discretas multigrupo tenemos que derivar un operador \mathcal{a}(\psi,v) : V^{MG} \times V^{MG} \mapsto \mathbb{R} y un funcional \mathcal{B}(v) : V^{MG} \mapsto \mathbb{R} de forma tal de re-escribir la formulación fuerte dada por la ecuación 3.16 en una formulación débil como
\begin{gathered} \text{encontrar $[\psi_{11}(\mathbf{x})~\cdots~\psi_{MG}(\mathbf{x})]^T \in V^{MG}$ tal que} \\ \mathcal{a} \Big([\psi_{11}~\cdots~\psi_{MG}]^T, [v_{11}~\cdots~v_{MG}]^T\Big) = \mathcal{B} \Big([v_{11}~\cdots~v_{MG}]^T)\Big) \quad \forall [v_{11}(\mathbf{x})~\cdots~v_{MG}(\mathbf{x})]^T \in V^{MG} \end{gathered}
Para ello, partimos de la la ecuación 3.16
\begin{gathered} \underbrace{\hat{\mathbf{\Omega}}_m \cdot \text{grad} \left[ \psi_{mg}(\mathbf{x}) \right]}_\text{advección} + \underbrace{\Sigma_{t g}(\mathbf{x}) \cdot \psi_{mg}(\mathbf{x})}_\text{absorciones} = \underbrace{\sum_{g^\prime=1}^G \Sigma_{s_0 g^\prime \rightarrow g}(\mathbf{x}) \sum_{m^\prime=1} w_{m^\prime} \psi_{m^\prime g^\prime}(\mathbf{x})}_\text{scattering isotrópico} + \\ \underbrace{3 \sum_{g^\prime=1}^G \Sigma_{s_1 g^\prime \rightarrow g}(\mathbf{x}) \sum_{m^\prime=1} w_{m^\prime} \left( \hat{\mathbf{\Omega}}_{m} \cdot \hat{\mathbf{\Omega}}_{m^\prime} \right) \psi_{m^\prime g^\prime}(\mathbf{x})}_\text{scattering anisótropo} + \underbrace{\chi_g \sum_{g^\prime=1}^G \nu\Sigma_{fg^\prime}(\mathbf{x}) \sum_{m^\prime=1} w_{m^\prime} \psi_{m^\prime g^\prime}(\mathbf{x})}_\text{fisiones} + \underbrace{s_{mg}(\mathbf{x})}_\text{fuentes} \end{gathered} y tal como hicimos con la ecuación de difusión, multiplicamos cada término por v_{mg}(\mathbf{x}), integramos sobre el dominio U \in \mathbb{R}^D, pasamos los términos de scattering y fisiones al miembro izquierdo y los sumamos. Podemos escribir los términos de absorciones, scattering y fisiones en forma similar al caso de difusión como
\int_U \begin{bmatrix}v_{11}(\mathbf{x}) & \cdots & v_{MG}(\mathbf{x})\end{bmatrix} \cdot \Big( \mathsf{R}(\mathbf{x}) - \mathsf{F}(\mathbf{x}) \Big) \cdot \begin{bmatrix}\psi_{11}(\mathbf{x}) \\ \vdots \\ \psi_{MG}(\mathbf{x})\end{bmatrix} d^D \mathbf{x} con las matrices cuadradas de secciones eficaces de remoción y \nu-fisiones de tamaño MG \times MG
\mathsf{R}(\mathbf{x}) = \begin{bmatrix} \Sigma_{t1} - w_1 \cdot \Sigma_{s_0~1 \rightarrow 1} & - w_1 \cdot \Sigma_{s_0~1 \rightarrow 2} & \cdots & - w_1 \cdot \Sigma_{s_0~1 \rightarrow G} & - w_1 \cdot \Sigma_{s_0~2 \rightarrow 1} & \cdots \\ \end{bmatrix}
\mathsf{X}(\mathbf{x}) = \begin{bmatrix} w_1 \chi_1 \nu\Sigma_{f1} & w_1 \chi_1 \nu\Sigma_{f2} & w_1 \chi_1 \nu\Sigma_{f1} & \cdots & w_1 \chi_1 \nu\Sigma_{fG} & w_1 \chi_2 \nu\Sigma_{f1} & \cdots \\ \end{bmatrix}
Pero ahora el término de advección es de primer orden
\int_U \begin{bmatrix}v_{11}(\mathbf{x}) & \cdots & v_{mg}(\mathbf{x}) & \cdots & v_{MG}(\mathbf{x})\end{bmatrix} \cdot \begin{bmatrix} \hat{\mathbf{\Omega}}_{1} \cdot \nabla \psi_{11}(\mathbf{x}) \\ \vdots \\ \hat{\Omega}_{mx} \cdot \frac{\partial \psi_{mg}}{\partial x} + \hat{\Omega}_{my} \cdot \frac{\partial \psi_{mg}}{\partial y} + \hat{\Omega}_{mz} \cdot \frac{\partial \psi_{mg}}{\partial z} \\ \vdots \\ \hat{\mathbf{\Omega}}_{M} \cdot \nabla \psi_{MG}(\mathbf{x}) \\ \end{bmatrix} d^D \mathbf{x}
Re-escribimos el vector \Omega_{m} \cdot \nabla \psi_{mg} como el producto de una matriz constante con los cosenos directores \mathsf{D} de tamaño MG \times MGD y un vector \boldsymbol{\psi}^\prime \in \mathbb{R}^{MG} de derivadas parciales de los MG flujos angulares con respecto a las D coordenadas
\begin{bmatrix} \hat{\Omega}_{1x} & 0 & \cdots & 0 & \cdots & 0 & \hat{\Omega}_{1y} & \cdots & 0 \\ 0 & \hat{\Omega}_{1x} & \cdots & 0 & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots & \ddots & \vdots & \vdots & \ddots & 0 \\ 0 & 0 & \cdots & \hat{\Omega}_{mx} & \cdots & 0 & 0 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots & \ddots & \vdots & \vdots & \ddots & 0 \\ 0 & 0 & \cdots & 0 & \cdots & \hat{\Omega}_{Mx} & 0 & \cdots & \hat{\Omega}_{Mz} \end{bmatrix} \cdot \begin{bmatrix} \partial \psi_{11}/\partial x \\ \partial \psi_{12}/\partial x \\ \vdots \\ \partial \psi_{mg}/\partial x \\ \vdots \\ \partial \psi_{MG}/\partial x \\ \partial \psi_{11}/\partial y \\ \vdots \\ \partial \psi_{MG}/\partial z \\ \end{bmatrix} = \begin{bmatrix} \hat{\mathbf{\Omega}}_{1} \cdot \nabla \psi_{11}(\mathbf{x}) \\ \hat{\mathbf{\Omega}}_{1} \cdot \nabla \psi_{12}(\mathbf{x}) \\ \vdots \\ \hat{\mathbf{\Omega}}_{m} \cdot \nabla \psi_{mg}(\mathbf{x}) \\ \vdots \\ \hat{\mathbf{\Omega}}_{M} \cdot \nabla \psi_{MG}(\mathbf{x}) \\ \end{bmatrix}
El operador \mathcal{a}\big([\psi_{11} \dots \psi_{MG}]^T, [v_{11} \dots v_{MG}]^T\big) : V^{MG} \times V^{MG} \mapsto \mathbb{R} que buscamos es
\begin{aligned} \mathcal{a}\big([\psi_{11} \dots \psi_{MG}]^T, [v_{11} \dots v_{MG}]^T\big) =& \int_U \begin{bmatrix}v_{11}(\mathbf{x}) & \cdots & v_{MG}(\mathbf{x})\end{bmatrix} \cdot \mathsf{D} \cdot \mathbf{\psi}^\prime(\mathbf{x}) d^D \mathbf{x} \\ & + \int_U \begin{bmatrix}v_{11}(\mathbf{x}) & \cdots & v_{MG}(\mathbf{x})\end{bmatrix} \Big( \mathsf{R}(\mathbf{x}) - \mathsf{F}(\mathbf{x}) \Big) \begin{bmatrix}\psi_{11}(\mathbf{x}) \\ \vdots \\ \psi_{MG}(\mathbf{x})\end{bmatrix} d^D \mathbf{x} \end{aligned}
Observación. El operador \mathcal{a}\big([\psi_{11} \dots \psi_{MG}]^T, [v_{11} \dots v_{MG}]^T\big) para ordenadas discretas no es simétrico y la mayoría de las veces tampoco es coercitivo.
Como en la formulación S_N las condiciones de contorno son sólo de Dirichlet, la única contribución al vector \mathbf{b} proviene del término de fuentes independientes. Entonces el funcional \mathcal{B}(v) : V^{MG} \mapsto \mathbb{R} es directamente
\mathcal{B}\big( [v_{11} \dots v_{MG}]^T\big) = \int_U \begin{bmatrix}v_{11}(\mathbf{x}) & \cdots & v_{MG}(\mathbf{x})\end{bmatrix} \cdot \begin{bmatrix}s_{11}(\mathbf{x}) \\ \vdots \\ s_{MG}(\mathbf{x})\end{bmatrix} d^D \mathbf{x}
En principio, estaríamos en condiciones de discretizar la variable espacial \mathbf{x} con las matrices \mathsf{H}_{MGc} y \mathsf{B}_{MG} tal como hemos hecho en la Sección 3.4.2.2 para la ecuación de difusión multigrupo, con la salvedad de que ahora hay MG grados de libertad por nodo espacial. Pero el hecho de que el operador no sea coercitivo hace que el método numérico basado en la aproximación de Galerkin no sea estable y por lo tanto no converja. Una forma de recuperar la coercitividad del operador \mathcal{a} y poder obtener una solución numérica al problema de ordenadas discretas formulado con un esquema de elementos finitos sobre la variable espacial \mathbf{x} es resolver un problema de Petrov-Galerkin en el cual cada una de las funciones de prueba v_{mg} vive en un espacio vectorial V^\prime_{N} diferente al espacio vectorial V_N donde viven las incógnitas \psi_{mg} para alguna elección adecuada de V^\prime_{N}.
Definición 3.26 (problema de Petrov-Galerkin) Sea V_N un sub-espacio de V = H^1_0(U) y sea V^\prime_N un sub-espacio de V^\prime = H^{\prime 1}_0(U), ambos de dimensión finita N Llamamos problema de Petrov-Galerkin a
\text{encontrar~} u_N \in V_N: \quad \mathcal{a} (u_N, v_N) = \mathcal{B} (v_N) \quad \forall v_N \in V^\prime_N
Para encontrar la formulación de Petrov-Galerkin del problema de transporte multigrupo de neutrones por ordenadas discretas, comenzamos aproximando las incógnitas de la misma manera que para el problema de Galerkin
\begin{bmatrix} \psi_{11}(\mathbf{x}) \\ \vdots \\ \psi_{MG}(\mathbf{x}) \\ \end{bmatrix} = \mathsf{H}_{MGc}(\mathbf{x}) \cdot \mathbf{\psi} donde \mathbf{\psi} \in \mathbb{R}^{MG} es un vector que contiene los valores nodales de los flujos angulares y \mathsf{H}_{MGc} es la matriz canónica de funciones de forma MG-aware. Pero como las funciones de prueba viven en otro espacio vectorial V^\prime_N, ahora
\begin{bmatrix} v_{11}(\mathbf{x}) \\ \vdots \\ v_{MG}(\mathbf{x}) \\ \end{bmatrix} = \mathsf{P}_{MGc}(\mathbf{x}) \cdot \mathbf{v} para un vector \mathbf{v} \in \mathbb{R}^{MG} con los valores nodales de las funciones de prueba pero para una matriz de Petrov \mathsf{P}_{MGc} con las funciones de forma que generan24 el espacio V^\prime_N. Entonces la formulación débil discretizada queda
\begin{gathered} \mathbf{v}^T \cdot \left[ \int_U \Big( \mathsf{P}^T_{MGc}(\mathbf{x}) \cdot \mathsf{D} \cdot \mathsf{H}_{MGc}(\mathbf{x}) + \mathsf{H}^T_{MGc} \cdot \big( \mathsf{R}(\mathbf{x}) - \mathsf{X}(\mathbf{x}) \big) \cdot \mathsf{H}_{MGc}(\mathbf{x}) \Big) \, d^D \mathbf{x} \right] \cdot \mathbf{\psi} =\\ \mathbf{v}^T \cdot \left[ \int_U \Big( \mathsf{P}^T_{MGc}(\mathbf{x}) \cdot \mathbf{s}(\mathbf{x}) \Big) \, d^D \mathbf{x} \right] \end{gathered} lo que implica
\mathsf{K} \cdot \mathbf{\psi} = \mathbf{b}
De la misma manera que para difusión, la matriz de rigidez elemental de tamaño MGJ \times MGJ evaluada en el q-ésimo punto de Gauss \mathbf{\xi}_q es
\begin{aligned} \mathsf{K}_i &= \sum_{q=1}^Q \omega_q \cdot \Big|\det{\left[\mathsf{J}_i\left(\mathbf{\xi}_q\right)\right]}\Big| \cdot \left[ \mathsf{L}_i(\mathbf{\xi}_q) + \mathsf{A}_i(\mathbf{\xi}_q) - \mathsf{F}_i(\mathbf{\xi}_q)\right] \end{aligned} \tag{3.65}
a partir de las matrices elementales de pérdidas, absorciones y fisiones de tamaño MGJ \times MGJ
\begin{aligned} \mathsf{L}_i &= \mathsf{P}_{MGc}^T(\mathbf{\xi}_q) \cdot \mathsf{D} \cdot \mathsf{H}_{MGc}(\mathbf{\xi}_q) \\ \mathsf{A}_i &= \mathsf{P}_{MGc}^T(\mathbf{\xi}_q)^T \cdot \mathsf{R}(\mathbf{\xi}_q) \cdot \mathsf{H}_{MGc}(\mathbf{\xi}_q) \\ \mathsf{F}_i &= \mathsf{P}_{MGc}^T(\mathbf{\xi}_q)^T \cdot \mathsf{X}(\mathbf{\xi}_q) \cdot \mathsf{H}_{MGc}(\mathbf{\xi}_q) \end{aligned}
Observación. En FeenoX, la matriz de estabilización SUPG \mathsf{P}_{MGc} se calcula de la siguiente manera:
int MG = neutron_sn.directions * neutron_sn.groups;
double tau = feenox_var_value(neutron_sn.sn_alpha) * e->type->size(e);
gsl_matrix *H_G = feenox_fem_compute_H_Gc_at_gauss(e, q, feenox.pde.mesh->integration);
gsl_matrix *B = feenox_fem_compute_B_at_gauss(e, q, feenox.pde.mesh->integration);
feenox_call(gsl_matrix_memcpy(neutron_sn.P, H_G));
for (unsigned int j = 0; j < neutron_sn.n_nodes; j++) {
int MGj = MG*j;
for (unsigned int m = 0; m < neutron_sn.directions; m++) {
for (unsigned int d = 0; d < feenox.pde.dim; d++) {
double value = tau * neutron_sn.Omega[m][d] * gsl_matrix_get(B, d, j);
for (unsigned int g = 0; g < neutron_sn.groups; g++) {
int diag = sn_dof_index(m,g);
gsl_matrix_add_to_element(neutron_sn.P, diag, MGj + diag, value);
}
}
}
}3.5 Problemas de estado estacionario
Si bien en el capítulo 2 hemos mantenido por completitud la dependencia temporal explícitamente en los flujos y corrientes, en esta tesis resolvemos solamente problemas de estado estacionario. Tal como hemos hecho en este capítulo, al eliminar el término de la derivada con respecto al tiempo, las propiedades matemáticas de las ecuaciones cambian y por lo tanto debemos resolverlas en forma diferente según tengamos alguno de los siguientes tres casos:
- Medio no multiplicativo con fuentes independientes,
- Medio multiplicativo con fuentes independientes, y
- Medio multiplicativo sin fuentes independientes.
3.5.1 Medio no multiplicativo con fuentes independientes
Un medio no multiplicativo es aquel que no contiene núcleos capaces de fisionar. Cada neutrón que encontremos en el medio debe entonces provenir de una fuente externa s. Para estudiar este tipo de problemas, además de eliminar la derivada temporal y la dependencia con el tiempo, tenemos que hacer cero el término de fisión, por lo que \nu\Sigma_g = 0~\forall g. Luego la ecuación de difusión queda
\begin{gathered} - \text{div} \Big[ D(\mathbf{x}, E) \cdot \text{grad} \left[ \phi(\mathbf{x}, E) \right] \Big] + \Sigma_t(\mathbf{x}, E) \cdot \phi(\mathbf{x}, E) = \\ \int_{0}^{\infty} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \phi(\mathbf{x}, E^\prime) \, dE^\prime + s_0(\mathbf{x}, E) \end{gathered} \tag{3.66} y la de transporte
\begin{gathered} \hat{\mathbf{\Omega}}\cdot \text{grad} \left[ \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \right] + \Sigma_t(\mathbf{x}, E) \cdot \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) = \\ \frac{1}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \int_{4\pi} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}^\prime, E^{\prime}) \, d\hat{\mathbf{\Omega}}^\prime\, dE^\prime + \\ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_1}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \int_{4\pi} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}^\prime, E^{\prime}) \cdot \hat{\mathbf{\Omega}}^\prime\, d\hat{\mathbf{\Omega}}^\prime\, dE^\prime + s(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \end{gathered} \tag{3.67}
Para que la solución sea no trivial, el vector \mathbf{b} del miembro derecho debe ser no nulo lo que implica que
- la fuente no se debe anular idénticamente en el dominio, y/o
- las condiciones de contorno deben ser no homogéneas.
Si las secciones eficaces (incluyendo el coeficiente de difusión) dependen explícitamente de la posición \mathbf{x} pero no dependen del flujo \psi o \phi, entonces tanto la ecuación 3.66 como la 3.67 son lineales. Entonces tenemos un sistema de ecuaciones lineales que podemos escribir en forma matricial como
\mathsf{A}_N(\Sigma_N) \cdot \mathbf{\varphi}_N = \mathbf{b}_N(\Sigma_N) \tag{3.68} donde
- \mathbf{\varphi}_N es un vector de tamaño N \in \mathbb{N} que contiene los valores nodales de la incógnita (flujo angular \psi en transporte y flujo escalar \phi en difusión) asociada a cada uno de los grados de libertad del problema discretizado (cantidad de incógnitas espaciales, grupos de energía y/o direcciones),
- \mathsf{A}_N(\Sigma_N) \in \mathbb{R}^{N \times N} es una matriz rala25 cuadrada que contiene información sobre
- las secciones eficaces macroscópicas, es decir los coeficientes de la ecuacion que estamos resolviendo, y
- la discretización de los operadores diferenciales e integrales,
- \mathbf{b}_N(\Sigma_N) \in \mathbb{R}^N es un vector que contiene
- la versión discretizada de la fuente independiente s, y/o
- las condiciones de contorno no homogéneas
- N es el tamaño del problema discretizado, que es el producto de
- la cantidad J de incógnitas espaciales (cantidad de nodos en elementos finitos y cantidad de celdas en volúmenes finitos),
- la cantidad G de grupos de energía, y
- la cantidad M de direcciones discretas (sólo para el método de ordenadas discretas).
El vector \mathbf{\varphi}_N \in \mathbb{R}^N es la incógnita, que luego de resolver el sistema permitirá evaluar en forma aproximada (en el sentido de la Sección 3.1) la función \psi ó \phi en función de \mathbf{x}, E y eventualmente \hat{\mathbf{\Omega}} para todo punto del espacio \mathbf{x} dependiendo de la discretización espacial.
Si las secciones eficaces dependen directa o indirectamente del flujo, por ejemplo a través de concentraciones de venenos o de la temperatura de los materiales (que a su vez puede depender de la potencia disipada, que depende del flujo neutrónico) entonces el problema es no lineal. En este caso, tenemos que volver a escribir la versión discretizada en forma genérica 3.1
\tag{\ref{eq-generica-numerica}} \mathcal{F}_N(\mathbf{\varphi}_N, \Sigma_N) = 0 para alguna función vectorial \mathcal{F}_N : [\mathbb{R}^{N} \times \mathbb{R}^{N^\prime}] \mapsto \mathbb{R}^{N}.26 La forma más eficiente de resolver estos problemas es utilizar variaciones del esquema de Newton [1], donde la incógnita \mathbf{\varphi}_N se obtiene iterando a partir de una estimación inicial27 \mathbf{\varphi}_{N0}
\mathbf{\varphi}_{Nk+1} = \mathbf{\varphi}_{Nk} - \mathsf{J}_N(\mathbf{\varphi}_{Nk}, \Sigma_{Nk})^{-1} \cdot \mathcal{F}_N(\mathbf{\varphi}_{Nk}, \Sigma_{Nk}) para los pasos k=0,1,\dots, donde \mathsf{J}_N es la matriz jacobiana de la función \mathcal{F}_N. Dado que la inversa de una matriz rala es densa, es prohibitivo evaluar (¡y almacenar!) explícitamente \mathsf{J}_N^{-1}. En la práctica, la iteración de Newton se implementa mediante los siguientes dos pasos:
- Resolver \mathsf{J}(\mathbf{\varphi}_{Nk}, \Sigma_{Nk}) \cdot \Delta \mathbf{\varphi}_{Nk} = -\mathcal{F}_N(\mathbf{\varphi}_{Nk}, \Sigma_{Nk})
- Actualizar \mathbf{\varphi}_{Nk+1} \leftarrow \mathbf{\varphi}_{Nk} + \Delta \mathbf{\varphi}_{Nk}
Dado que la matriz de rigidez es el jacobiano de las iteraciones de Newton, la formulación discreta de la ecuación 3.68 es central tanto para problemas lineales como no lineales.
3.5.2 Medio multiplicativo con fuentes independientes
Si además de contar con fuentes independientes de fisión el medio contiene material multiplicativo, entonces los neutrones pueden provenir tanto de las fuentes independientes como de las fisiones. En este caso, tenemos que tener en cuenta la fuente de fisión, cuyo valor en la posición \mathbf{x} es proporcional al flujo escalar \phi(\mathbf{x}). En la Sección 2.1.3 indicamos que debemos utilizar expresiones diferentes para la fuente de fisión dependiendo de si estamos resolviendo un problema transitorio o estacionario. Si bien solamente una fracción 1-\beta de todos los neutrones nacidos por fisión se generan en forma instantánea, en el estado estacionario debemos también sumar el resto de los \beta como fuente de fisión ya que suponemos el estado encontrado es un equilibrio instante a instante dado por los 1-\beta neutrones prompt y \beta neutrones retardados que provienen de fisiones operando desde un tiempo t=-\infty.
El tipo de problema discretizado es esencialmente similar al caso del medio no multiplicativo con fuentes de la sección anterior, sólo que ahora la matriz \mathsf{A}_N(\Sigma_N) contiene información sobre las fuentes de fisión, que son lineales con la incógnita \mathbf{\varphi}_N. Estos casos se encuentran al estudiar sistemas sub-críticos como por ejemplo piletas de almacenamiento de combustibles gastados o procedimientos de puesta a crítico de reactores.
3.5.3 Medio multiplicativo sin fuentes independientes
En ausencia de fuentes independientes, podemos escribir las ecuaciones de transporte y difusión continuas genéricamente como [14]
\frac{\partial \varphi}{\partial t} = \mathcal{L}\left[\varphi(\mathbf{x},\hat{\mathbf{\Omega}}, E,t)\right] \tag{3.69} donde \varphi = \psi para transporte y \varphi = \phi para difusión (sin dependencia de \hat{\mathbf{\Omega}}), y \mathcal{L} es un operador lineal homogéneo de primer orden en el espacio para transporte y de segundo orden para difusión. Esta formulación tiene infinitas soluciones de la forma
\varphi(\mathbf{x},\hat{\mathbf{\Omega}}, E,t) = \varphi_n(\mathbf{x},\hat{\mathbf{\Omega}}, E) \cdot e^{\alpha_n \cdot t} que al insertarlas en la ecuación 3.69 definen un problema de autovalores ya que
\begin{aligned} \frac{\partial}{\partial t} \left[ \varphi_n(\mathbf{x},\hat{\mathbf{\Omega}}, E) \cdot e^{\alpha_n \cdot t} \right] &= \mathcal{L}\left[\varphi_n(\mathbf{x},\hat{\mathbf{\Omega}}, E) \cdot e^{\alpha_n\cdot t} \right] \\ \alpha_n \cdot \varphi_n(\mathbf{x},\hat{\mathbf{\Omega}}, E) \cdot e^{\alpha_n\cdot t} &= \mathcal{L}\left[\varphi_n(\mathbf{x},\hat{\mathbf{\Omega}}, E) \cdot e^{\alpha_n\cdot t} \right] \\ \alpha_n \cdot \varphi_n(\mathbf{x},\hat{\mathbf{\Omega}}, E) &= \mathcal{L}\left[\varphi_n(\mathbf{x},\hat{\mathbf{\Omega}}, E)\right] \end{aligned} donde ni \alpha_n ni \varphi_n dependen del tiempo t.
La solución general de la ecuación 3.69 es entonces
\varphi(\mathbf{x},\hat{\mathbf{\Omega}}, E,t) = \sum_{n=0}^\infty C_n \cdot \varphi_n(\mathbf{x},\hat{\mathbf{\Omega}},E) \cdot \exp(\alpha_n \cdot t) donde los coeficientes C_n son tales que satisfagan las condiciones iniciales y de contorno.
Si ordenamos los autovalores \alpha_n de forma tal que \text{Re}(\alpha_n) \ge \text{Re}(\alpha_{n+1}) entonces para tiempos t\gg 1 todos los términos para n \neq 0 serán despreciables frente al término de \varphi_0. El signo de \alpha_0 determina si la población neutrónica
- disminuye con el tiempo (\alpha_0 < 0),
- permanece constante (\alpha_0 = 0), o
- aumenta con el tiempo (\alpha_0 > 0).
La probabilidad de que en un sistema multiplicativo sin una fuente independiente (es decir, un reactor nuclear de fisión) el primer autovalor \alpha_0 sea exactamente cero para poder tener una solución de estado estacionario no trivial es cero. Para tener una solución matemática no nula, debemos agregar al menos un parámetro real que permita ajustar uno o más términos en forma continua para lograr ficticiamente que \alpha_0 = 0. Por ejemplo podríamos escribir las secciones eficaces en función de un parámetro \xi que podría ser
- geométrico (por ejemplo la posición de una barra de control o las fugas si fuese posible modificar la geometría), o
- físico (por ejemplo la concentración media de boro en el moderador).
De esta forma, podríamos encontrar un valor de \xi que haga que \alpha_0 = 0 y haya una solución de estado estacionario.
Hay un parámetro real—en el sentido matemático—que, además de permitir encontrar una solución no trivial para cualquier conjunto físicamente razonable de geometrías y secciones eficaces, nos da una idea de qué tan lejos se encuentra el modelo de la criticidad. El procedimiento consiste en dividir el término de fisiones por un número real k_\text{eff} > 0, para obtener la ecuación de difusión como
\begin{gathered} - \text{div} \Big[ D(\mathbf{x}, E) \cdot \text{grad} \left[ \phi(\mathbf{x}, E) \right] \Big] + \Sigma_t(\mathbf{x}, E) \cdot \phi(\mathbf{x}, E) = \\ \int_{0}^{\infty} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \phi(\mathbf{x}, E^\prime) \, dE^\prime + \frac{1}{k_\text{eff}} \cdot \chi(E) \int_{0}^{\infty} \nu\Sigma_f(\mathbf{x}, E^\prime) \cdot \phi(\mathbf{x}, E^\prime) \, dE^\prime \end{gathered} y la de transporte como
\begin{gathered} \hat{\mathbf{\Omega}}\cdot \text{grad} \left[ \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) \right] + \Sigma_t(\mathbf{x}, E) \cdot \psi(\mathbf{x}, \hat{\mathbf{\Omega}}, E) = \\ \frac{1}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_0}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \int_{4\pi} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}^\prime, E^{\prime}) \, d\hat{\mathbf{\Omega}}^\prime\, dE^\prime + \\ \frac{3 \cdot \hat{\mathbf{\Omega}}}{4\pi} \cdot \int_{0}^{\infty} \Sigma_{s_1}(\mathbf{x}, E^{\prime} \rightarrow E) \cdot \int_{4\pi} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}^\prime, E^{\prime}) \cdot \hat{\mathbf{\Omega}}^\prime\, d\hat{\mathbf{\Omega}}^\prime\, dE^\prime \\ + \frac{1}{k_\text{eff}} \cdot \frac{\chi(E)}{4\pi} \int_{0}^{\infty} \nu\Sigma_f(\mathbf{x}, E^\prime) \cdot \int_{4\pi} \psi(\mathbf{x}, \hat{\mathbf{\Omega}}^\prime, E^{\prime}) \, d\hat{\mathbf{\Omega}}^\prime\, dE^\prime \end{gathered}
La utilidad del factor k_\text{eff} queda reflejada en la siguiente definición.
Definición 3.27 Llamamos factor de multiplicación efectivo al número real k_\text{eff} por el cual dividimos la fuente de fisiones de las ecuaciones que modelan un medio multiplicativo sin fuentes externas. Al nuevo medio al cual se le han dividido sus fuentes de fisión por k_\text{eff} lo denominamos reactor crítico asociado en k. Si k_\text{eff}>1 entonces el reactor original estaba super-crítico ya que hubo que disminuir sus fisiones para encontrar una solución no trivial, y viceversa. El flujo solución de las ecuaciones es el flujo del reactor crítico asociado en k y no del original, ya que si el original no estaba crítico entonces éste no tiene solución estacionaria no nula.
Al no haber fuentes independientes, todos los términos están multiplicados por la incógnita y la ecuación es homogénea. Sin embargo, ahora habrá algunos términos multiplicados por el coeficiente 1/k_\text{eff} y otros no. Una vez más, si las secciones eficaces dependen sólo de la posición \mathbf{x} en forma explícita y no a través del flujo, entonces el problema es lineal y al separar en ambos miembros estos dos tipos de términos obtendremos una formulación discretizada de la forma
\mathsf{A}_N(\Sigma_N) \cdot \mathbf{\varphi}_N = \lambda_N \cdot \mathsf{B}(\Sigma_N) \cdot \mathbf{\varphi}_N \tag{3.70} conformando un problema de autovalores generalizado, donde el autovalor \lambda_N dará una idea aproximada de la criticidad del reactor y el autovector \mathbf{\varphi}_N la distribución de flujo del reactor crítico asociado en k. Si \mathsf{B}(\Sigma_N) contiene los términos de fisión entonces \lambda_N = 1/k_{\text{eff}N} y si \mathsf{A}_N(\Sigma_N) es la que contiene los términos de fisión, entonces \lambda = k_{\text{eff}N}.
En general, para matrices de N \times N habrá N pares autovalor-autovector. Más aún, tanto el autovalor \lambda_n como los elementos del autovector \mathbf{\varphi}_n en general serán complejos. Sin embargo se puede probar [6] que, para el caso \lambda=1/k_{\text{eff}N} (\lambda=k_{\text{eff}N}),
- hay un único autovalor positivo real que es mayor (menor) en magnitud que el resto de los autovalores,
- todos los elementos del autovector correspondiente a dicho autovalor son reales y tienen el mismo signo, y
- todos los otros autovectores o bien tienen al menos un elemento igual a cero o tienen elementos que difieren en su signo
Tanto el problema continuo como el discretizado en la ecuación 3.70 son matemáticamente homogéneos. Esta característica define dos propiedades importantes:
El autovector \mathbf{\varphi}_N (es decir el flujo neutrónico) está definido a menos de una constante multiplicativa y es independiente del factor de multiplicación k_{\text{eff}N}. Para poder comparar soluciones debemos normalizar el flujo de alguna manera. Usualmente se define la potencia térmica total P del reactor y se normaliza el flujo de forma tal que
P = \int_{U} \int_0^\infty e\Sigma_f(\mathbf{x}, E) \cdot \phi(\mathbf{x}, E) \, dE \, d^3\mathbf{x} donde e\Sigma_f es el producto entre la la energía liberada en una fisión individual y la sección eficaz macroscópica de fisión. Si P es la potencia térmica instantánea, entonces e\Sigma_f debe incluir sólo las contribuciones energéticas de los productos de fisión instantáneos. Si P es la potencia térmica total, entonces e\Sigma_f debe tener en cuenta todas las contribuciones, incluyendo aquellas debidas a efectos retardados de los productos de fisión.
Las condiciones de contorno también deben ser homogéneas. Es decir, no es posible fijar valores de flujo o corrientes diferentes de cero.
Observación. Las secciones 5.3, 5.5, 5.6, 5.7, 5.8 y 5.10 contienen casos de este tipo de problemas.
Si, en cambio, las secciones eficaces macroscópicas dependen directa o indirectamente del flujo neutrónico (por ejemplo a través de la concentración de venenos hijos de fisión o de la temperatura de los componentes del reactor a través de la potencia disipada) entonces el problema de autovalores toma la forma no lineal
\mathsf{A}_N(\mathbf{\varphi}_N,\Sigma_N) \cdot \mathbf{\varphi}_N = \lambda_N \cdot \mathsf{B}(\mathbf{\varphi}_N,\Sigma_N) \cdot \mathbf{\varphi}_N
Existen esquemas numéricos eficientes para resolver problemas de autovalores generalizados no lineales donde la no linealidad es con respecto al autovalor \lambda_N [13]. Pero como en este caso la no linealidad es con el autovector \mathbf{\varphi}_N (es decir, con el flujo) y no con el autovalor (es decir el factor de multiplicación efectivo), no son aplicables.
En el caso de neutrónica no lineal tenemos que resolver iterativamente
\mathsf{A}(\mathbf{\varphi}_{Nk},\Sigma_{Nk}) \cdot \mathbf{\varphi}_{Nk+1} = \lambda_{Nk+1} \cdot \mathsf{B}(\mathbf{\varphi}_{Nk},\Sigma_{Nk}) \cdot \mathbf{\varphi}_{Nk+1} a partir de una solución inicial \mathbf{\varphi}_{N0}. En este caso el flujo está completamente determinado por la dependencia (explícita o implícita) de \mathsf{A} y \mathsf{B} con \mathbf{\varphi}_N y no hay ninguna constante multiplicativa arbitraria.
Terminada la explicación del cómo en estos capítulos 2 y 3, pasemos entonces al qué en los dos capítulos que siguen.
Machinery and circuits are formal languages.↩︎
Del inglés spanned.↩︎
En el sentido matemático de satisfacer exactamente la ecuación diferencial. El análisis de la exactitud física queda fuera del alcance de esta tesis.↩︎
Del inglés strongly.↩︎
Del inglés fully.↩︎
En el sentido del inglés wall time.↩︎
Del inglés cloud native como contrapartida a cloud friendly o cloud enabled.↩︎
Del inglés unstructured grids.↩︎
Del inglés hosts.↩︎
Podríamos haber integrado la ecuación de difusión, en cuyo caso no tendríamos el denominador 4\pi en ambos miembros. En cualquier caso, el resultado sería el mismo.↩︎
Del ingles piecewise constant.↩︎
Equivalentes a la figura 6.4 de la página 205 de [14] y a la figura 4.3 de la página 161 de [9].↩︎
En en apéndice B mostramos cómo aprovechar la elipticidad del operador de Laplace para resolver un laberinto arbitrario.↩︎
Del inglés test funcion.↩︎
Llamamos volumen al dominio de dimensión D y superficie a la frontera de dimensión D-1.↩︎
Técnicamente es un affine manifold.↩︎
En la gran mayoría de la literatura de elementos finitos las funciones de forma se llaman N(\mathbf{x}). Como este símbolo no nos parece apropiado para una función del espacio, seguimos la nomenclatura de Bathe [2] (que fue director de doctorado del Dr. Dvorkin que a su vez organizó el departamento de cálculo de la UBA donde este doctorando cursó la materia de elementos finitos) que utiliza la nomenclatura h(\mathbf{x}) para las funciones de forma.↩︎
Si bien la nomenclatura usual es llamar v_j a los componentes del vector \mathbf{v}, dejamos el subíndice para indicar grupos de energía al discretizar las ecuaciones de neutrónica en las secciones que siguen.↩︎
Para un problema con G >1 grados de libertad por nodo el tamaño es GJ \times GJ.↩︎
Cuando las coordenadas se interpolan con las funciones de forma del elemento estamos ante elementos isoparamétricos. Existen también elementos sub-paramétricos y super-paramétricos. En este trabajo, siempre utilizamos elementos isoparamétricos.↩︎
Estrictamente hablando, esta no es la formulación sino que es una de las varias formulaciones posibles. De todas maneras es la más usual y eficiente.↩︎
Como para el problema de elasticidad al multiplicar la formulación fuerte por las funciones de prueba y aplicar la fórmula de Green se obtiene el principio de los trabajos virtuales, a veces estas funciones de prueba se llaman “desplazamientos virtuales”. Como generalización, en el problema de conducción de calor se las llaman “temperaturas virtuales” [2]. En este caso, tal como ya propusimos en [15], podríamos llamarlas “flujos escalares virtuales”.↩︎
Del inglés leakage.↩︎
Del inglés span.↩︎
Del inglés sparse.↩︎
El tamaño N^\prime de la información relacionada con los datos de entrada \Sigma_N no tiene por que ser igual al tamaño N del vector solución.↩︎
El término correcto es initial guess.↩︎